Toward AGI — What is Missing?

Artificial General Intelligence (AGI) is a term for Artificial Intelligence systems that meet or exceed human performance on the broad range of tasks that humans are capable of performing. There are benefits and downsides to AGI. On the upside, AGIs can do most of the labor that consume a vast amount of humanity’s time and energy. AGI can herald a utopia where no one has wants that cannot be fulfilled. AGI can also result in an unbalanced situation where one (or a few) companies dominate the economy, exacerbating the existing dichotomy between the top 1% and the rest of humankind. Beyond that, the argument goes, a super-intelligent AGI could find it beneficial to enslave humans for its own purposes, or exterminate humans so as to not compete for resources. One hypothetical scenario is that an AGI that is smarter than humans can simply design a better AGI, which can, in turn, design an even better AGI, leading to something called hard take-off and the singularity.
I do not know of any theory that claims that AGI or the singularity is impossible. However, I am generally skeptical of arguments that Large Language Models such the GPT series (GPT-2, GPT-3, GPT-4, GPT-X) are on the pathway to AGI. This article will attempt to explain why I believe that to be the case, and what I think is missing should humanity (or members of the human race) so choose to try to achieve AGI. I will also try to convey a sense for why it is easy to talk about the so-called “recipe for AGI” in the abstract but why physics itself will prevent any sudden and unexpected leap from where we are now to AGI or super-AGI.
2. What is Missing?
To achieve AGI it seems likely we will need one or more of the following:
- Online non-greedy planning technologies that can operate in the presence of a priori unseen tasks, states, and actions. This may be reinforcement learning or something else. The challenge here is to be able to represent and reason about states and actions that are task agnostic or can change the representations based on tasks that have never been seen before. We may also need the ability to generalize or transfer across unseen states, actions, and tasks to reduce the amount of costly exploration of possible future states and actions. However, there is no way to completely eliminate the need for exploration.
- A world model technology that robustly predicts state-action-state transitions for all states and actions that might be encountered while performing any task in any environment. Such a world model would enable fast online planning (using reinforcement learning or otherwise). To learn such a world model would require data of real-world state-action transitions, which in turn will require the ability to explore and interact with the real world.
- If Large Language Models (LLMs) are to be used in AGI, we may require one of the following: (a) a reinforcement learning agent that wraps an LLM in a traditional trial-and-error training loop; (b) a reinforcement learning from human feedback technique that factors in states and goals and rewards for successful transitions and goal achievement.
The three missing capabilities are inexorably linked. Planning is a process of deciding which actions to perform to achieve a goal. Reinforcement learning — the current favorite path forward — requires exploration of the real world to learn how to plan, and/or the ability to imagine how the world will change when it tries different actions. A world model can predict how the world will change when an agent attempts to perform an action. But world models are best learned through exploration.
Large Language Models are exciting because they seem to know so much about the world. LLMs have some world model-like qualities but typically not at the level of specificity needed for acting reliably in the real world. Reinforcement Learning with Human Feedback lacks the context of a real world state to evaluate actions against. This requires planning or a world model.
I will break down these arguments in detail in the next sections.
1. Planning
The most fundamental capability missing from Large Language Models is online non-greedy planning.
Planning refers to one of two things:
- A processes of finding a sequence of actions <a₁, a₂, …> that transforms the current state of the world into one in which a goal situation holds
- A process of finding a policy that maps states to actions π: S → A such that executing action a = π(s) in any state s ∈ S encountered by the agent and following the policy henceforth will maximize expected reward.
The result of planning is either a plan — a sequence of actions to follow — or a policy — a mapping that indicates the action to follow for any state encountered.
A hallmark of planning is exploration: any process whereby alternative actions are evaluated with respect to whether they improve the agent’s situation with respect to either a goal or expected future reward. There are a few known mechanisms for exploration. Two relevant ones are:
- Backtracking: a process by which an algorithm can revisit earlier decisions to make different choices. This is used in planning algorithms such as A*, UCPOP, and modern planners such as Fast-Downward.
- Rollouts: a process by which different alternatives are considered along with the possible future state-action trajectories that are possible after each alternative. The algorithm generates different possible futures and analyzes them to figure out which immediate alternative results in the best set of possible futures. This is used in algorithms such as Minimax and Monte Carlo Tree Search. A special case of rollouts is restarts, in which an agent returns to an initial state and tries again but makes different decisions along the way. This is used in reinforcement learning.
A greedy planner makes a choice between alternatives using local information in order to cut down on the computational complexity of analyzing all alternatives. Greedy algorithms tend to be fast, but also cannot provide optimality bound guarantees. The most extreme version of a greedy planner does a single rollout without any backtracking and doesn’t evaluate any actions or states with regard to their goal or future expected reward.
Online planning refers to planning that is done at execution time because there are state conditions and environmental constraints that may only be known at the time of execution.
Because non-greedy online planning can be slow, offline planning can be used to generate a policy that maps any state to the best action to take. The resulting policy can be run very fast at execution time; no matter what state the agent ends up in after executing an action, the next action to execute is available as quickly as π can be queried. This is the typical use of reinforcement learning, which is a class of algorithms to produce a policy. One might think of reinforcement learning as pre-exploration of the state-action space.
In theory, when an offline planner such as reinforcement learning can sufficiently pre-explore the state-action space, then running the policy at execution time is equivalent to online planning. In practice, this is not always possible.
Why should we require online planning for AGI?
- There is an infinite number of tasks that might be performed. Many will be derivations of each other and so generalization across tasks will go a long way. But there will be tasks that are unique enough that an offline pre-trained policy model will not transfer. There will also be known tasks that must be conducted in situations novel enough to require new considerations.
- There is an infinite number of states in the real world. Generalization will be a powerful mechanisms for handling novel states and actions. But there will be some states that are unique enough that a policy model will not perform as desired without additional online considerations.
- The “rules of the world” may change with the introduction of new technologies, new ways of doing things, changing preferences for how things are done.
Why should we require non-greedy planning for AGI?
- We might not necessarily always require optimal solutions to tasks, but we might want plans to be reasonably efficient and effective. The less greedy an algorithm, the less susceptible to being trapped in local maxima.
1.1 Reinforcement Learning
Reinforcement learning is a class of algorithms that solve a Markov Decision Process M=<S, A, P, R, γ> where S is the set of all possible states, A is the set of all possible actions, P is a transition function P: S × A × S → [0,1], R is a reward function R: S × A → ℝ, and γ = [0, 1] is a discount factor proportional to the reward horizon. The solution to an MDP is a policy π: S → A as described above. In practice, AI agents don’t always know what state they are in and must solve a partially-observable MDP (POMDP), however in practice with deep reinforcement learning we can often treat S as the set of possible state observations and solve POMDPs as if they are MDPs.
Actions with non-deterministic effects are handled without any significant changes to the problem formulation because the policy can tell us what action to execute next, no matter what state we end up in after executing an action.
In the case where the state-action space is too large to enumerate, a compact representation must be learned that approximates the optimal policy. This is the case of deep reinforcement learning, which learns a deep neural network that can generate an action in response to a state, which is referred to as a policy model.
There are two broad classes of reinforcement learning:
- Model-based RL uses the transition function P to conduct rollouts without directly interacting with the environment.
- Model-free RL handles the case where P is unknown and learns the policy directly from interactions with the environment. The environment can either be the actual environment the agent will be executing in, or a simulation.
One can also use a simulation to learn the transition function (which we will later call a “world model”) and then perform model-based RL; this sometimes converges on a policy faster than model-free RL. Model-based RL can be used to perform online or offline planning, whereas model-free RL is usually best suited for offline planning.
Deep RL is a popular class of algorithms through which to pursue AGI because it theoretically handles the non-determinism of acting in the real world and theoretically deal with the large state-action space of the real world.
1.2 Planning with Large Language Models
The first thing to observe about large language models is that they are not natively planners. That is, they don’t do it without some help. As feed-forward networks they do not have any mechanism — recursive or iterative — that allows allows them to revisit prior decisions or perform rollouts. This is a somewhat pedantic argument, because LLMs are wrapped in code that performs sampling. However, the most typical sampling and generation does not evaluate alternatives with respect to a goal or a reward.
One exception is beam search, though there is no evidence that any commercial LLMs use beam search. Beam search is semi-greedy in that it generates alternatives, but those alternatives are usually evaluated with a substitute scoring function like perplexity that does not take into account goal or future reward. Reinforcement Learning with Human Feedback (RLHF) and Reinforcement with AI Feedback (RLAIF) are also exceptions that we will discuss more thoroughly later.
Despite the above, LLMs can generate text that looks like plans:
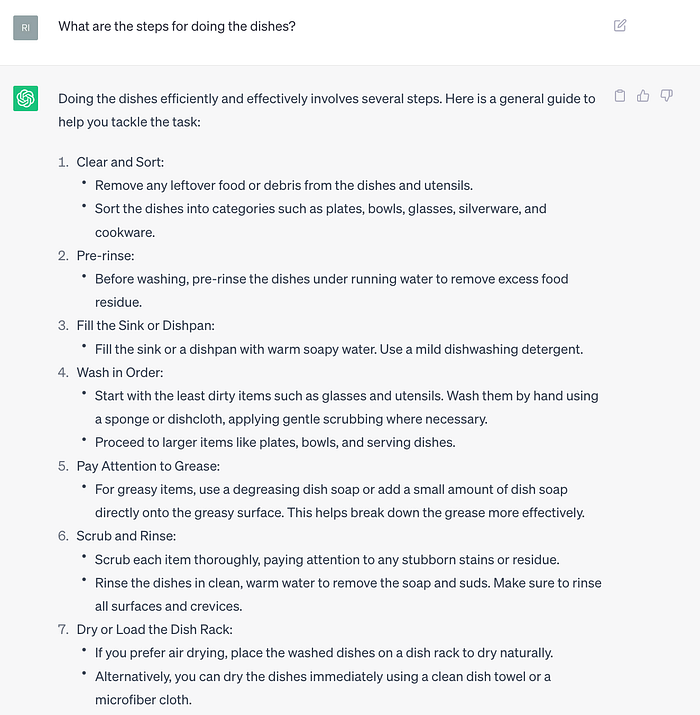
Based on previous discussion, we can say that LLMs are greedy planners. There are a few caveats to note:
- If LLMs are planners, then tokens are actions. Whereas what we might think of as actions from the context of execution in the real world would be the latent semantic meaning of sequences of tokens (or in the case of code generation, actions could be literal strings that are syntactically correct). We might therefore have to say that LLMs as planners are operating on a different set of primitives than those that can be executed directly in the real world.
- There is no native means of handling feedback from the world when a generated plan is being executed. That is, if a planned action is unexecutable, information about the failure and the reason for the failure must be reported back so that the planner can choose an alternative action and/or generate a new plan from scratch in such a way that the same cause of failure is avoided later.
These caveats can be addressed by mechanisms outside the LLM.
1.2 RLHF and RLAIF
Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) have been successful for tuning LLMs. RLHF is a process of collecting feedback from humans on the performance of an LLM on different tasks and converting that feedback into additional training signal. RLAIF is a process of algorithmically judging the output of an LLM — typically by a second AI model — and converting it to additional training signal (a form of distant supervision).
Both RLHF and RLAIF (henceforth RL*F) use the following process to fine-tune an LLM:
- An LLM produces several responses to a prompt
- Each response is assessed and given a score (for example +1 for a good response, -1 for a bad response)
- The score fore each response is converted into loss and back-propagated through the LLM causing the model to shift its distribution so that it either generates more responses like the previous one or fewer responses like the previous one.
What makes the above a reinforcement learning process instead of a typical supervised learning process is that the LLM is forced to roll out several complete, distinct responses per prompt and the feedback is only applied at the end of each rollout. Thus every token is an action and the feedback is “sparse” because it is only applied at the end of a sequence of actions.
The RL*F process can be thought of as an offline planning process. During execution time, the LLM — now a policy model — must pick the actions (tokens) that would maximize expected reward if reward were to be given (reward is not given at execution time because the model is trained and it is no longer available or necessary).
But what is the reward that the reinforcement learning process is attempting to maximize? This is where things get interesting. The objective is now: select tokens that will be seen as being responsive to the prompt (i.e., “follow instructions”) because this will get the best feedback.
There are some important implications to the objective function. First, instead of having a fixed goal, the “goal” is provided in the prompt. In this sense, the LLM-cum-policy is being asked to achieve a goal without knowing what goals it will be presented with during training time. This is different than a lot of systems that use reinforcement learning, like playing Go, where the goal is always the same and the agent can explore a lot of states and actions and evaluate those states and actions with respect to goal achievement.
Second, a RL*F tuned LLM can be said to be trying to generate sequences that appear to follow instructions. Why? Because the system never evaluates any states or actions with respect to any goal or reward other than the likelihood of receiving positive human feedback. The feedback used in tuning is not whether the goal in the prompt is successfully achieved by the generated response. Indeed the provider of feedback — human or another model — cannot know because there is no actual world against which to evaluate the plan. All that can be provided is whether the plan looks correct in the general sense (in general, this is what one must do to clean dishes, though your kitchen and circumstances may be different and the plan is un-executable as-is). Thus we can say that what the LLM-cum-policy learns is whether it is generating something that looks approximately correct.
We can say that RL*F-tuned LLMs are offline planners, but not planning for the goals we think they are being given, and not at the level of abstraction of actions executable in the world.
2. World Models
A world model is a model of the state-action transition dynamics: P(s’ | s, do(a)), the probability of arriving in state s’ from state s if action a is performed. A world model — previously referred to as the transition function in an MDP — allows an agent to perform rollouts without interacting with the actual execution environment. Informally, we can say the world model enables an agent to “imagine” the consequences of different alternatives. This is roughly analogous to the way humans are able to imagine and anticipate the consequences of their actions, and this seems to help when solving tasks.
It has been demonstrated that deep RL agents that either have a hard-coded world model (e.g., AlphaGo) or learn a world model alongside the policy model (e.g., MuZero, Dreamer, etc.) can learn faster than model-free RL approaches because the presence of a world model — even a partially learned one — reduces exploration and number of interactions with the simulation environment.
2.1. World Models and Large Language Models
Do LLMs have world models? Somewhat. If I prompt ChatGPT with “Sally gave John the book. Who has the book now?” it will tell me:
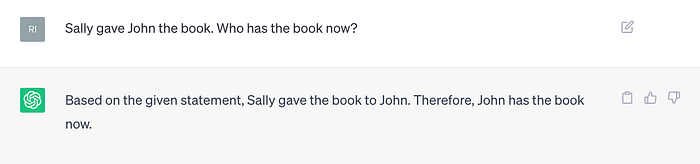
“Based on the given statement, Sally gave the book to John. Therefore, John has the book now.” It has some trouble figuring out who had the book first, but that isn’t strictly required of a world model:
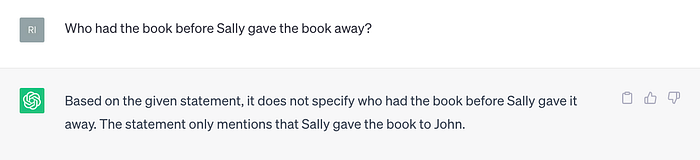
ChatGPT can also sort of play chess. This is an interesting case because to know what actions it can take, it must have some sort of representation of the state of the board, right?

How did it know that d5 was a legal move? It doesn’t. It knows that a lot of chess games recorded on the internet using that notation has d5 following d4. Farther into the game it will make illegal moves because there are a lot of possible games and any sequence of moves will have been seen less often in the data. But clearly the hidden state of the transformer is able to attend to a sequence of moves and that the hidden state that is constructs has some utility for selecting tokens that can be interpreted as chess actions. Thus it can be said that a LLM has something that can operate as a world model sometimes. It operates at the lower level of tokens and constructs a textual description of the state, as opposed to the actual state.
Here is another test of whether ChatGPT knows the state of the chess board after a single chess move:
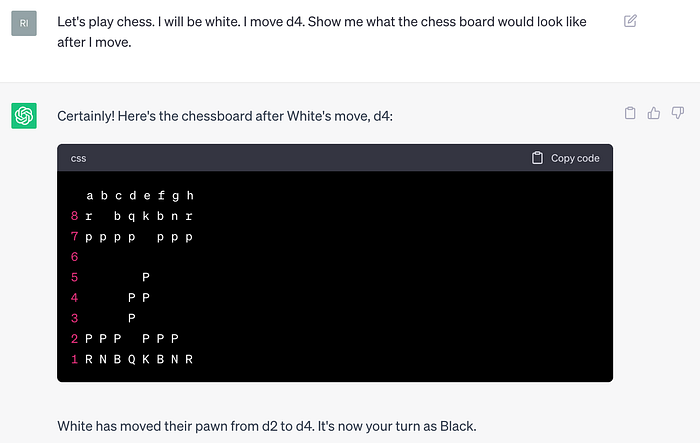
Clearly not right. But this test is not entirely conclusive because I am asking it to draw the board and maybe it gets confused in the drawing process; something might be lost in this particular way of probing the system’s understanding of the state.
There is nothing in RL*F that requires that a world model must be correct. This is because there is no reward component associated with correct next-state prediction. An LLM only needs be able to construct a hidden state that can be decoded to generate token sequences that receive high feedback or low perplexity. However, operating with only cross-entropy or RL*F at the token-as-action level, there is no requirement that a LLM develops full world-model capabilities beyond whatever latent hidden state is necessary to produce token sequences that receive high feedback or low perplexity.
If LLMs are learning something like a world model, would we expect a world model to emerge with more training? This likely depends on the data. As discussed above there is nothing in the objective function used to train LLMs that requires the model to know and reason about the next state s’. If the training corpus were of the form <description of state s, description of action a, description of state s’> (or a combination of separate <s, a> and <a, s> data) then it would learn to construct a subsequent state after every action, token-by-token. For some relatively constrained domains, this data might be present in existing datasets or feasible to acquire. For other domains, the state-action space will be too big and there will be missing data, rare cases for which generalization fails to account, or a mismatch in level of abstraction of knowledge.
2.2. World Models in State-Based Reinforcement Learning
World models have been very successful in reinforcement learning in computer games and in robotics. The ability to predict the results of one’s own action and evaluate that result against a reward function means that more rollouts can happen faster.
The challenge has been the chicken-and-egg relationship between state-based reinforcement learning and learning world models. To learn a world model, an agent must experiment with different actions in different states to see what happens. This is very similar (and sometimes exactly the same) as the process required to learn a reinforcement learning policy itself. They are often learned simultaneously, though sometimes the world model can be learned first, slowly, and the policy can be learned quickly afterwards.
While a world model helps a reinforcement learning agent learn a policy faster (even if it is learned side-by-side with the policy), the current suite of RL algorithms only learn a world model that is good enough to help with the current policy. This means that when an agent is required to stray from tasks or environments it has seen before, the world model doesn’t help out. If the goal is to achieve some reward, there is no incentive for the world model to retain any knowledge about the environment that is not directly relevant to the policy.
Open-endedness refers to the challenge of tackling new tasks and new environments without additional training. One approach is to accept that an agent (like a human) can never be fully trained and prepared to tackle all new tasks and environments. Another approach is to get an agent that is capable of generalizing as much as possible and then use online planning to consider new variables, tasks, rewards, and environmental conditions.
4. RL and World Model Bottlenecks
Reinforcement learning and planning are computationally expensive processes. This may be due to the fact that we haven’t yet discovered better ways of training policy models. However, as we understand it today, RL algorithms must either have data that covers all state-action transitions in advance, or it must generate its own data by interactively exploring the execution environment (or simulation). This results in data acquisitions bottlenecks.
- RLHF requires human feedback. As RLHF is done right now, goals are part of the prompt; to be better at more tasks, more human feedback is required. Human feedback can only be acquired at a human time-scale. That is, improving RLHF is rate-limited.
- RLHF cannot use human feedback to evaluate plan correctness because the world state is not known when feedback is presented. If human feedback is to be provided in response to actual attempt to execute plans, then a human must be “in the loop” during exploration and feedback can only be acquired as fast as plans can be executed in the real world with human oversight.
- RLAIF uses an AI model to generate reward. This AI feedback model is often trained using human data, the acquisition of which is rate-limited.
- Regardless of whether LLMs are used or not, there is no simulation environment that is complex enough to train a general AI system. It must be capable of faithfully expressing any task that might be pursued in the real world or the agent that trains in the environment will not be general. To have a general model capable of generating policies that are robust or plans that are sound, an agent must execute in the real world, which is rate-limited by the physics of action execution and the lack of the ability to properly do resets. A simulation environment can be generated. However, to learn to build a simulation environment requires the same state-action trial-and-error data needed to train the agent in the first place.
- The alternative to having a simulation environment is to have a world model. While LLMs have some capability to act as a world model, world-model-like capabilities in LLMs are incomplete and often at the wrong level of abstraction for execution in the real world. To learn a world model will require interactions with the real world or human feedback, both of which are addressed above.
- RL works best when the the goal/reward function is always the same and the agent can reset to the same — or similar — starting state. The dirty secret is that RL policies are overfit with respect to their rewards/goals, which makes them quite formidable in closed-world environments like games. However, learning a policy while the goal or reward keeps changing is extremely challenging and requires very strong generalization, or zero-shot transfer, or require more interactions with the environment while avoiding catastrophic forgetting. Online planning can achieve novel goals, but requires a world model (probably in conjunction with re-planning capabilities) and is extremely computationally inefficient since it requires online exploration and/or online trials.
5. Other Bottlenecks
One way to deal with data acquisition and RL trial bottlenecks is through parallelization. Two RL agents running trials and/or using federated learning to share model updates can explore twice as much of a state-action space in the same amount of time as one. More agents running in parallel can do even more.
One might ask whether it is possible to continuously increase the number of agents running in parallel until a policy model or a world model is learned at (or above) human level nearly instantaneously? Unchecked replication scenarios will run into real-world constraints. Where do the new agents get the computing power? Where do the new agents get the electricity? Neither can grow exponentially because they are physical resources that must be produced via non-trivial real-world processes. There are a lot of GPUs in the world, but not all are accessible, and it takes time and materials to build more. Electricity is also a finite resource and it takes time to build new power production facilities.
Furthermore, if the data can only be acquired via embodied (robotic) trials in the real world, then robotic actuators are also a resource bottleneck. If human feedback is required, then feedback data cannot be acquired faster than humans can provide it; parallelization means more humans will be needed and compensated.
Can an agent of sufficient complexity and capability design and build an agent that is more complex? Theoretically yes. If human experts can design increasingly better algorithms, processors, energy sources, then a human-level AGI can build a better AGI. However, design of a better system requires trial-and-error (aka the scientific process). If it didn’t, we would have already have built that better system. The trial-and-error process involves acting in the real world if we are talking about hardware. Again, operating in the real world is a rate-limited process.
Simulators attempt to get around around real-world rate limits. There are, for example, very good chip-design simulators based on our current understanding of physics. If the agents are software only and fit within computational hardware constraints, then there is still a process of iterating on the software/algorithm/model, training, and testing. This iteration loop might be tighter than hardware design, but non-zero. However, to avoid the situation where subsequent agents are solely confabulation machines, I assume that the process of designing an agent will involve something like RL, and that the second-order agent will need to be tested with regard to its ability to operate in the real world, bringing in rate limits on testing in the real world or the need to have already acquired world models by acting in the real world.
Is all the knowledge needed to self-improve to, or above, human parity already available? One argument is that an LLM can be trained on a larger pool of text than a human might conceivably read in a lifetime. Therefore an LLM-based agent can be more knowledgeable than a human. In some ways, current LLMs are more “knowledgeable” than humans. However, that knowledge is somewhat abstract due to the nature of what information is shared in text on the internet. That is, our text corpora are not at the level of granularity of operating in the real world — it is abstract knowledge because human-human communication doesn’t need all the finite details because humans are already embedded and practiced at operating in the real world. For example: in the abstract, I know how to perform a government coup.
In practice, however, conditions on the ground are unknowable in advance and require online planning, the pre-exploration of all contingencies, or a world model that allows planning or pre-exploration without interacting with the real world. The bottlenecks for all of these have already been discussed. Similarly, having read Machiavelli, I know in the abstract how to acquire power and influence, yet putting the principles into action is not guaranteed — it is not an instruction manual at an operational level, and even if it was, enacting a plan would require contingencies requiring online planning capability.
But maybe an AGI or super-AGI doesn’t need to operate in the real world if it can co-opt humans as universal robots into operating on the real world. Is it possible that an AGI or super-AGI, having processed vastly more text than any human, can put together all the pieces of information necessary to convince humans to do its bidding? This is akin to asking if there is a combination of existing knowledge sources that could make someone capable of obtaining power over others without practice or contingencies that wouldn’t have already been found. Perhaps this combination features thousands or millions of pieces of scattered source material, which an LLM can digest but a human cannot.
The above scenario is probably equivalent to having the data needed to form a perfect world model for a scenario from reading alone. The reason for the equivalency is that any sort of trial-and-error exploration on top will operate at a physics-limited or human-limited rate and be directly observable by humans who will then have an opportunity to choose to intervene.
Given the RL and world model learning bottlenecks that require either a lot of pre-exploration or a lot of exploration during online planning, the rate at which hypothetical AI systems can self-improve will be slow and probably need to happen out in the open, either through direct interaction with the real world, interaction with people in the real world, or through increased collection of human feedback data. One question that arises is whether humans can be manipulated into being complicit with the self-improvement process. Unfortunately the existence of QAnon suggests that some people are easily manipulated.
We still need an AI system that can get itself to the point that it understands how its words impact the recipient, so we must assume that someone has already allowed this to happen even when factoring in the aforementioned learning rate limits. Further, it is not a question of manipulating anyone, but manipulating the people who have power and access to provide resources that an AI system needs. How many people would that be? How does the AI system get access to people who have access? How many of them would be more susceptible to manipulation? Getting resources, whether more compute, nuclear materials, or biological materials is non-trivial. The people that hypothetical AI systems need to carry out their plans are exactly those who we would hope to be less susceptible to manipulation or on guard, or have checks-and-balances in place. That is, these scenarios require those who already have phenomenal levels of resources and access to be intentionally complicit or intentionally malicious.
6. Conclusions
There is no theory that says we cannot achieve AGI or super-AGI. We probably have the tools we need: large language models, reinforcement learning, planning, and world models. While it would be easy to say knowing the general tools makes AGI and super-AGI inevitable, it overlooks the bottlenecks that make the assembly of plausible systems from these generic tools slow. There is a reason that humans require dozens of years of interacting in the real world, and in social situations to become functioning adults. New breakthroughs are needed that will overcome the bottlenecks of data acquisition through human feedback or physical interaction with the real world. However, these bottlenecks are substantial and chipping away at learning efficiency may not be sufficient. The bottlenecks are grounded in physics and the rate at which humans can operate; the breakthroughs would need to be truly revolutionary instead of incremental.
Unless we find a way to construct AGI-level online planning or world models that do not befall the bottlenecks, then the appearance of AGIs and super-AGIs will not be spontaneous events or accidents. It will require substantial time out in the open, or Herculean efforts by malicious humans to hide the development.
Regulation that targets transparency will help make sure that appropriate response to any developments that are concerning can be timely. Regulation on transparency also helps in the cases of narrow AI systems that might violate societal norms of fairness, privacy, and appropriateness.
