Human-Centered Artificial Intelligence
The term Human-Centered Artificial Intelligence is a recognition that the future is increasingly putting humans in contact with artificial intelligences.
At the heart of human-centered AI is the recognition that the way AI systems solve problems — especially using machine learning — is fundamentally alien to humans without training in computer science or AI. When consumer-facing AI systems are significantly more sophisticated than Siri, Alexa, or Cortana, what will it take for my mother to feel comfortable using these systems? Human-centered AI is also a recognition that humans can be inscrutable to AI systems. AI systems do not grow up immersed in a society and culture in the way humans do.
I present a desideratum on the legs of human-centered AI:
- AI systems need to be able to understand humans
- AI systems need to help humans understand them
- Computational creativity
(As a desideratum, I note that there may be other essential components.)

I will use research out of my own research lab to illustrate the three pillars.
Understanding Humans
Many artificial intelligence systems that will come into contact with humans will need to understand how humans behave and what they want. This will make them more useful and also safer to use. For the foreseeable future, we will design AI systems that receive their instructions and goals from humans.

However, misunderstanding the human’s intent leads to failure. Beyond simply failing to understand human speech, consider the fact that perfectly understood instructions can lead to failure if part of the instructions or goals are unstated or implict.
Commonsense failure goals occur when the AI system does not achieve the desired result because part of the goal, or the way the goal should have been achieved is left unstated (in related work, this is also referred to as a corrupted reward). Why would this happen? One reason is that humans are used to communicating with other humans who share common knowledge about how the world works and how to do things. It is easy to fail to recognize that computers do not share this common knowledge and can take things too literally. The failure is not the fault of the AI system — it is the fault of the human operator.
Consider the example of asking a robot to go to a pharmacy and pick up a prescription drug. Because the human is ill, he or she would like the robot to return as quickly as possible. If the robot goes directly to the pharmacy, goes behind the counter, grabs the drug, and returns home, it will have succeeded and minimized execution time and resources (money). We would also say it stole the drugs because it did not exchange money for the drugs.
Reinforcement learning is a machine learning technique in which the system uses trial-and-error to learn which actions maximized expected future reward. It is fairly trivial to set up a scenario that fails as in the above example.
One solution to avoiding commonsense goal failures is for AI systems to have commonsense knowledge. This can be any knowledge commonly shared by individuals from the same society and culture. This can be anything from declarative knowledge (e.g., cars drive on the right side of the road) to procedural knowledge (e.g., a waitperson in a restaurant will not bring the bill until it is requested). While there have been several efforts to create knowledge bases of declarative commonsense knowledge, there is a dearth of knowledge readily available on procedural commonsense knowledge.

In my research, I have proposed that AI systems can learn procedural commonsense knowledge by reading stories written by individuals from a particular society and culture.
The Quixote system (bonus points for figuring out why we called it “Quixote” learns how to behave by listening to stories about common, everyday procedures like going to restaurants, going on dates, catching airplanes, or picking up orders from a pharmacy. Quixote evaluates it actions — it gets reward — for performing sequences of actions that emulate those of characters in the stories it receives.
Details on the Quixote system are beyond the scope of this post, but details can be found here. A video of Quixote in action is below after having processed a number of stories about going to pharmacies.
The key point is that we never told Quixote what stealing is (taking without compensating) or that it is bad. Quixote naturally avoids the behavior because the stories feature the pattern of paying first before leaving. It prefers to act this way because it receives reward for following social conventions instead of just achieving the end goal.

To the extent that it is impossible to enumerate the “rules” of society, which is more than just the laws, learning from stories can help AI systems and robots interact with humans more safely. Social conventions often exist to help avoid humans avoid conflict with each other, even though they may inconvenience us.
For more information on Quixote and learning from stories see the technical paper and the argument for learning ethics from stories.
AI Systems Helping Humans Understand Them
Invariably, an AI system or autonomous robotic system will make a mistake, fail, violate an expectation, or perform an action that confuses us. Our natural inclination is to want to ask “why did you do that?”
There has been a lot of work on “opening the black box” to figure out what was going on inside the autonomous system’s mind. A lot of that work is focused on visualizing neural networks because it is very hard to understand how neural networks come to a conclusion based on data given. It is hard even for AI experts to dig into neural networks. This work is geared toward AI power user, often for the purposes of debugging and improving an AI.
However, if we want to achieve a vision of autonomous systems being used by end users and operating around people, we must consider non-expert human operators. Non-experts have very different needs when it comes to interacting with autonomous systems. This type of operator is likely not looking for a very detailed inspection of the inner workings of the algorithm, but is more likely to want evidence of a mind at work that is aware of what is going on and responding to the environment (the autonomous system was doing what it thought was right but at the same time may be perceived as being unintelligent because of the failure or strange behavior). What can the autonomous system do to create the perception of intelligence, to assure the human that it was performing to the best of its ability, to instill confidence in its performance?
We take inspiration from how humans respond to the question “why did you do that?”. Humans rationalize. That is, humans produce an explanation after the fact that plausibly justifies their actions. They do not explain how their brains work — indeed, they likely do not know how their brains work. In turn, we accept these rationalizations knowing that they are not absolutely accurate reflections on the cognitive and neural processes that produced the behavior at the time.
AI Rationalization, therefore, is the task of creating an explanation comparable to what a human would say if he or she were performing the behavior that the robot was performing in the same situation. It is our hypothesis that AI rationalization will promote feelings of trust, rapport, and comfort in non-experts operating autonomous systems and robots. AI rationalization does not reflect what is actually happening in the underlying AI algorithm. It doesn’t help us understand the AI algorithm. But rationalization is fast, and therefore useful in time-critical situations.
Here is an autonomous agent playing a game of Frogger and rationalizing its behavior:
In this video, the agent is a standard reinforcement learning agent which has learned to play after many thousands of trials. Why does it do what it does? The technically correct answer is that for any state it experiences, it has tried many possible actions and discovered that one action leads to greater expected reward (called a Q value). It picks the action with the greatest Q value. The point is that you should not need to know what a Q value is to effectively use an autonomous system.
Our approach to AI rationalization is as follows. We first collect language data from humans performing a task and speaking out loud as they describe what they are doing. We then train a deep neural network to translate state and action information into natural language. We can then train an agent to perform the task separately, using whatever technique is most appropriate (we use reinforcement learning, but it really can be a black box). As the autonomous system performs actions, one can log those states and actions and send them through the translation neural network. The insight is that the states and actions act like an internal, robotic language and that we can translate that internal, robotic language into natural language. In our work, we literally grab the python data structures (arbitrarily designed to make the agent work effectively) and turn them into strings of 1s and 0s. The neural network is a standard sequence-to-sequence network with attention used in many language translation tasks.

More information on AI rationalization and our solution.
AI Rationalization is probably not the entire solution. It addresses a very high-level need for explanation and cannot answer questions in which a human asks for elaboration or more detail. AI Rationalization is likely one of a set of techniques that meet different levels of need.
Understanding Humans and Explanation Are Complimentary Technologies
One of the most exciting recent discoveries in my lab is that teaching AI systems to understand humans and teaching AI systems to explain their behaviors to humans are complimentary. The techniques that we developed to generate rationalizations of behaviors can be used to speed up learning of behaviors.

We took the neural network used to generate AI Rationalizations and flipped the inputs and outputs. That is, instead of training the neural network to translate the AI’s internal data representations into natural language, we trained the neural network to translate natural language into state and action data structures.

We then developed a specialized reinforcement learning technique that would look at the language generated for a state that it had never seen before and find correlations in the language to describe states that it had seen before. This would give the agent a clue about what to do. The agent was able to learn faster than standard reinforcement learning.
At the time of writing, the research has not been published yet, but here’s the punchline:
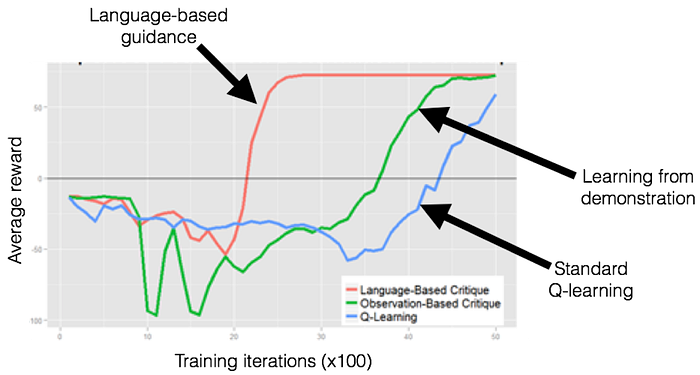
All techniques eventually get to optimal performance (top of the y-axis). But our new technique got there faster.
Computational Creativity
We’ve seen an explosion of interest and advances in computational creativity, where AI systems generate art, music, poetry, etc. Some of the most amazing (largely because of their visual nature), have been in AI painting and style transfer.

Besides the fact that this looks cool and is fun to play with, why should we care about advances in computational creativity? Why do I consider it one of the legs of the stool on Human-Centered AI?
Most of the recent successes in computational creativity have been about using machine learning (more specifically neural networks) to learn a pattern from data and then try to modify new inputs fit the pattern. This is what is happening in StyleNet (upper left corner of the above image), for example. A neural network learns something about the style of a piece of art. When presented with a picture of a cat, it iteratively modifies the pixels until it makes the neural network that learned the style happy. The same is true of DeepDream, which modifies images so that an image recognition neural network achieves higher activation (in this case creating eyes and puppy dog noses because there are a lot of examples of those in the data set). This is an imitative form of creativity.
Computational creativity is about gracefully handling novel situations (inputs) that it was never trained for. To deploy AI systems in the real world, they are going to face situations that are fundamentally different from anything they have experienced before in their historical data sets. The world is a messy, complicated place. In some of those cases, trying to fit the new situation into existing situations will be the wrong response, and possibly even dangerous.
AI can’t reach human-level creative problem solving without making intuitive leaps — to be able to extrapolate from the known to the unknown. Humans seem to be good at making intuitive leaps. We aren’t perfect, we also make mistakes. Maybe it is because we have more experience with the real world and our AI systems just need more data. Humans seem to have intentional control over the creative process that AI systems do not yet seems to possess. Regardless, AI systems can’t augment human creativity or work side by side with humans to solve problems if the AI system can’t keep up with the human collaborator’s intuitive leaps.
In my research, my team is trying to build an AI system that can autonomously generate a fully functional, enjoyable, and novel computer game from scratch. Computer game generation is an interesting test case for computational creativity because the artifact — the game — is dynamic. The human plays the game, meaning the AI system must come to understand how the artifact will be used. In art and music generation the question of how the artifact affects the observer can often be overlooked.
In one experiment, we trained an AI computer game generator to create a level of Super Mario Bros. that was an underwater castle. The system learned about level design from watching video of people playing the original game (paper on the technique here). The significance of this is that there are no examples of underwater castles in the original game. And yet the system must make something functional that appears plausible.

Our solution was to develop a technique for blending multiple learned models of different parts of the game (underwater levels, castle levels, etc.), essentially discovering a new part of the space of all possible designs that could not have been discovered from learning alone.
In future work, we would like to generate entire games that exist in a space of game design parameters that have never been seen by humans or by machine learning systems. Our aspiration is to be able to do something like this:

In other work, we look at creative improvisation: how to respond rapidly to a dynamically changing context. We hold theatrical improvisation as the gold standard of improvisational problem solving.
Concluding Thoughts
Human-Centered Artificial Intelligence recognizes the importance of humans in the environment that we hope to one day deploy AI systems and autonomous robotics. To make these technologies useful for everyday humans, and for humans to want to adopt these technologies into their lives and societies, AI must appear less “alien”. That does not mean that AI systems must think like humans or learn like humans. But the underlying hypothesis is that they must make themselves accessible and communicate on a level that humans are comfortable and familiar with. As of now, we humans are hard-wired to be effectively communicators and collaborators with other humans. Instead of making humans learn how AI systems reason, Human-Centered AI is about making AI and robotic systems understand how humans reason, communicate, and collaborate.
This in turn will make autonomous AI and robotics systems safer to use because they will not make commonsense goal errors or violate user expectations or inadvertently place themselves in situations that can lead to conflict and harm.
Finally, computational creativity is about gracefully handling new inputs and making intuitive leaps so that AI systems and robots can be effective collaborators with humans during problems solving in complex worlds.
It is my hypothesis that Human-Centered AI is an essential mix of capabilities necessary to bring autonomous AI and robotic systems out of the labs (and factories) and into the human world where they can exist and collaborate safely along side us in everyday contexts.
[This article is based on a presentation of the same title I gave at YConf in June 2017.]
