A Very Gentle Introduction to Large Language Models without the Hype
1. Introduction
This article is designed to give people with no computer science background some insight into how ChatGPT and similar AI systems work (GPT-3, GPT-4, Bing Chat, Bard, etc). ChatGPT is a chatbot — a type of conversational AI built — but on top of a Large Language Model. Those are definitely words and we will break all of that down. In the process, we will discuss the core concepts behind them. This article does not require any technical or mathematical background. We will make heavy use of metaphors to illustrate the concepts. We will talk about why the core concepts work the way they work and what we can expect or not expect Large Language Models like ChatGPT to do.
Here is what we are going to do. We are going to gently walk through some of the terminology associated with Large Language Models and ChatGPT without any jargon. If I have to use jargon, I will break it down without jargon. We will start very basic, with “what is Artificial Intelligence” and work our way up. I will use some recurring metaphors as much as possible. I will talk about the implications of the technologies in terms of what we should expect them to do or should not expect them to do.
Let’s go!
1. What is Artificial Intelligence?
But first, let’s start with some basic terminology that you are probably hearing a lot. What is artificial intelligence?
- Artificial Intelligence: An entity that performs behaviors that a person might reasonably call intelligent if a human were to do something similar.
It is a bit problematic to define artificial intelligence by using the word “intelligent”, but no one can agree on a good definition of “intelligent”. However, I think this still works reasonably well. It basically says that if we look at something artificial and it does things that are engaging and useful and seem to be somewhat non-trivial, then we might call it intelligent. For example we often ascribe the term “AI” to computer-controlled characters in computer games. Most of these bots are simple pieces of if-then-else code (e.g., “if the player is within range then shoot else move to the nearest boulder for cover”). But if we are doing the job of keeping us engaged and entertained, and not doing any obviously stupid things, then we might think they are more sophisticated than the are.
Once we get to understand how something works, we might not be very impressed and expect something more sophisticated behind the scenes. It all depends on what you know about what is going on behind the scenes.
They key point is that artificial intelligence is not magic. And because it is not magic, it can be explained.
So let’s get into it.
2. What is Machine Learning?
Another term you will often hear associated with artificial intelligence is machine learning.
- Machine Learning: A means by which to create behavior by taking in data, forming a model, and then executing the model.
Sometimes it is too hard to manually create a bunch of if-then-else statements to capture some complicated phenomenon, like language. In this case, we try to find a bunch of data and use algorithms that can find patterns in the data to model.
But what is a model? A model is a simplification of some complex phenomenon. For example, a model car is just a smaller, simpler version of a real car that has many of the attributes but is not meant to completely replace the original. A model car might look real and be useful for certain purposes, but we can’t drive it to the store.

Just like we can make a smaller, simpler version of a car, we can also make a smaller, simpler version of human language. We use the term large language models because these models are, well, large, from the perspective of how much memory is required to use them. The largest models in production, such as ChatGPT, GPT-3, and GPT-4 are large enough that it requires massive super-computers running in data center servers to create and run.
3. What is a Neural Network?
There are many ways to learn a model from data. The Neural Network is one such way. The technique is roughly based on how the human brain is made up of a network of interconnected brain cells called neurons that pass electrical signals back and forth, somehow allowing us to do all the things we do. The basic concept of the neural network was invented in the 1940s and the basic concepts on how to train them as were invented in the 1980s. Neural networks are very inefficient, and it wasn’t until around 2017 when computer hardware was good enough to use them at large scale.
But instead of brains, I like to think of neural networks using the metaphor of electrical circuitry. You don’t have to be an electrical engineer to know that electricity flows through wires and that we have things called resistors that make it harder for electricity to flow through parts of a circuit.
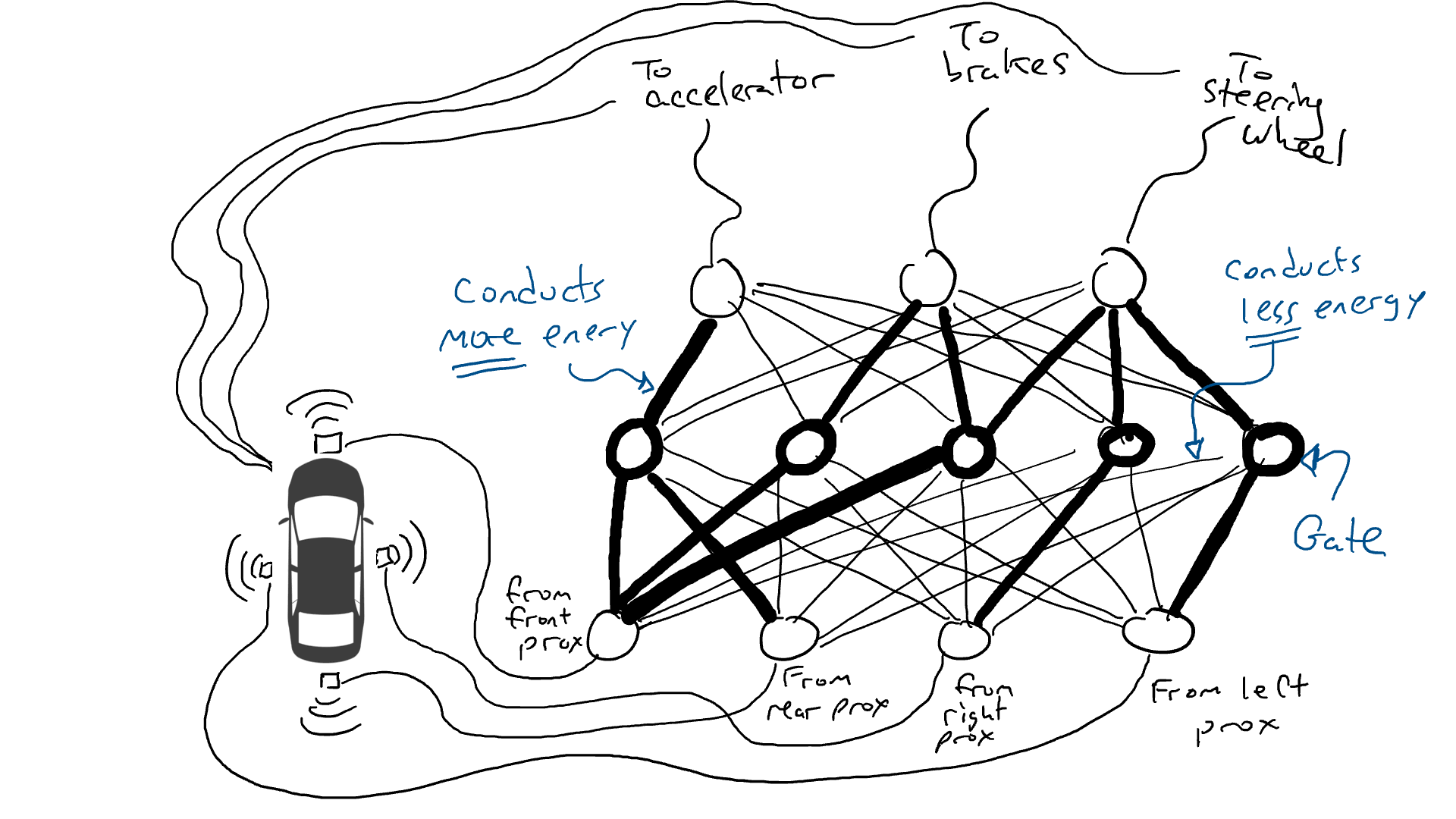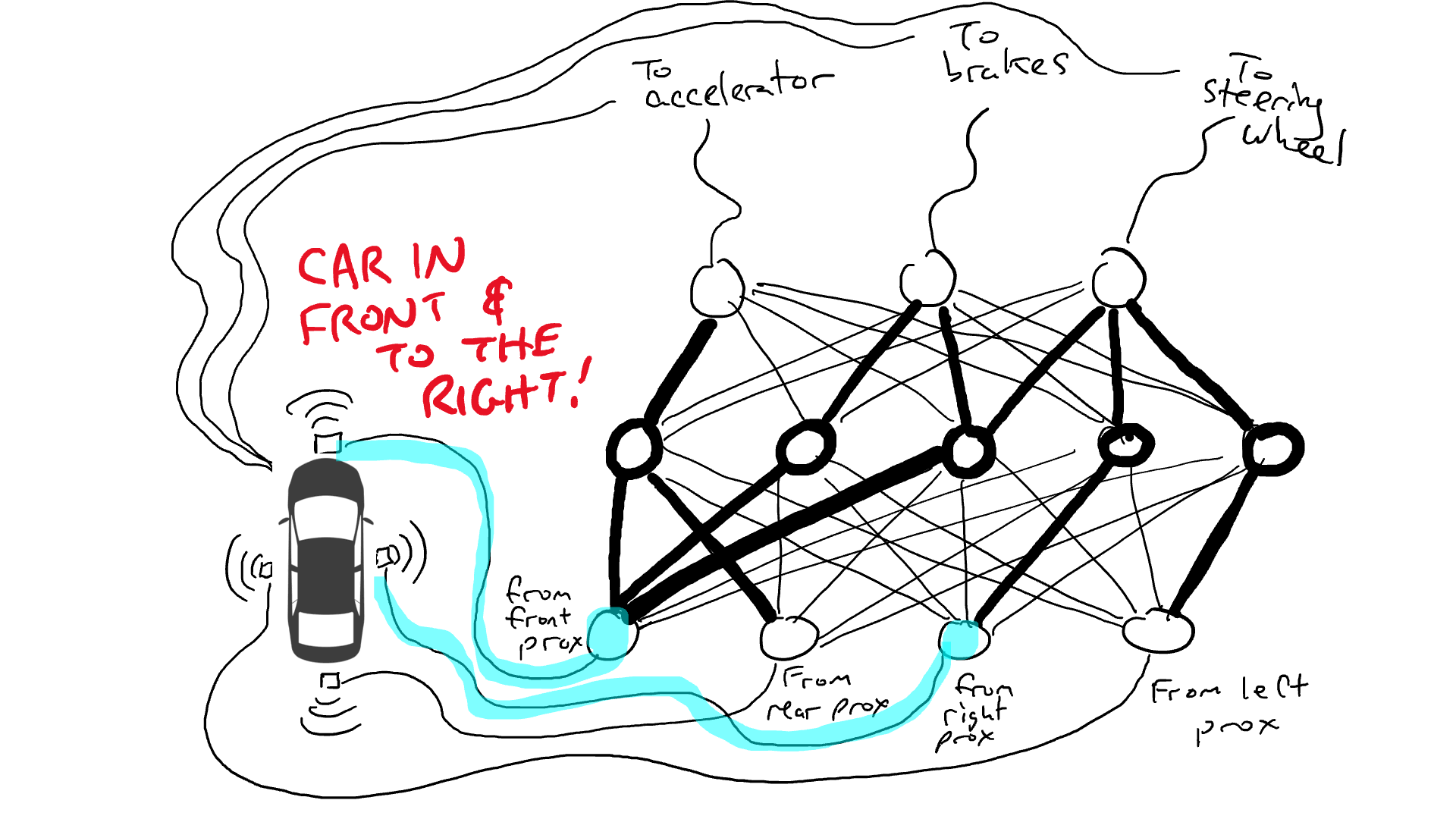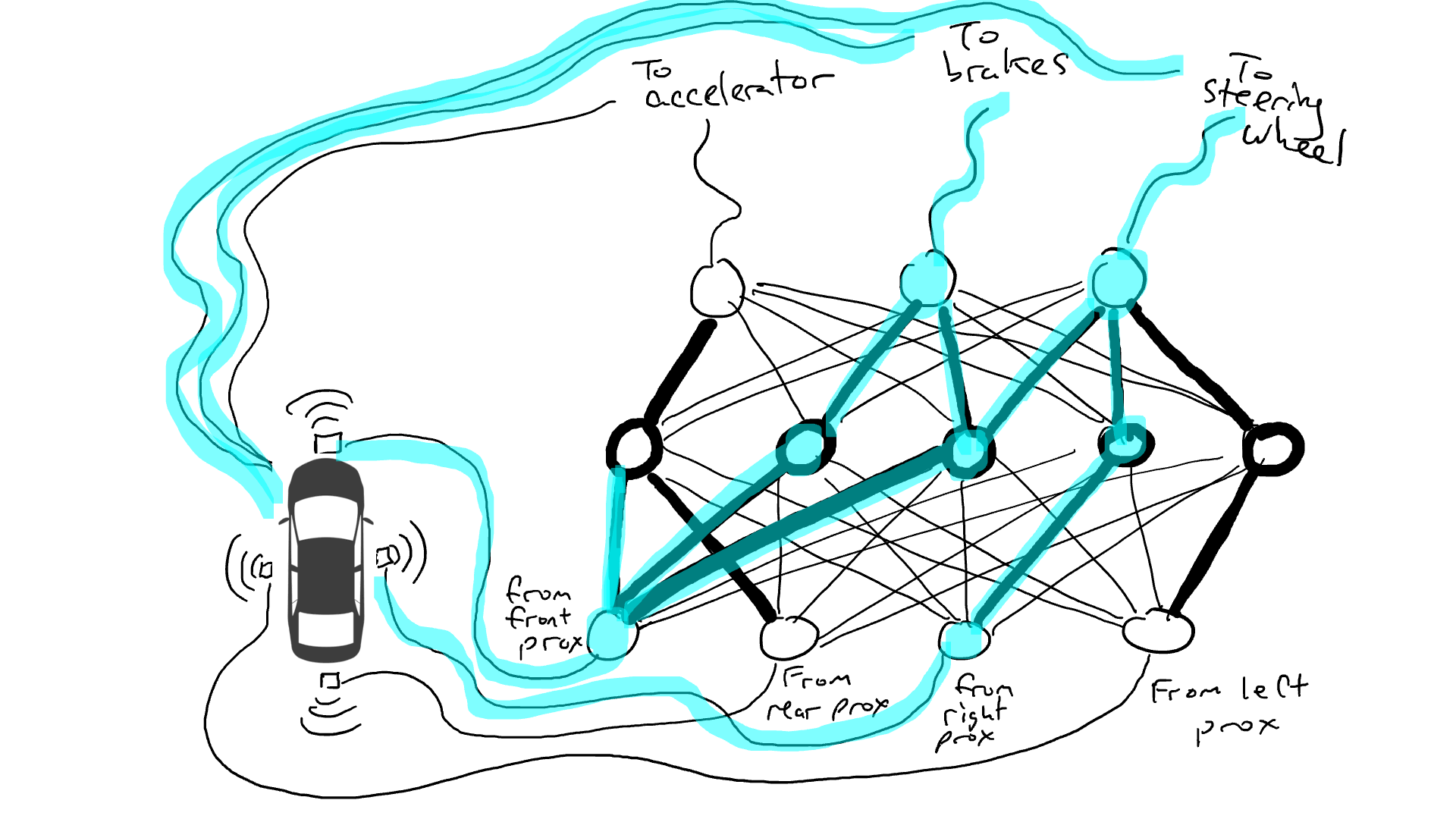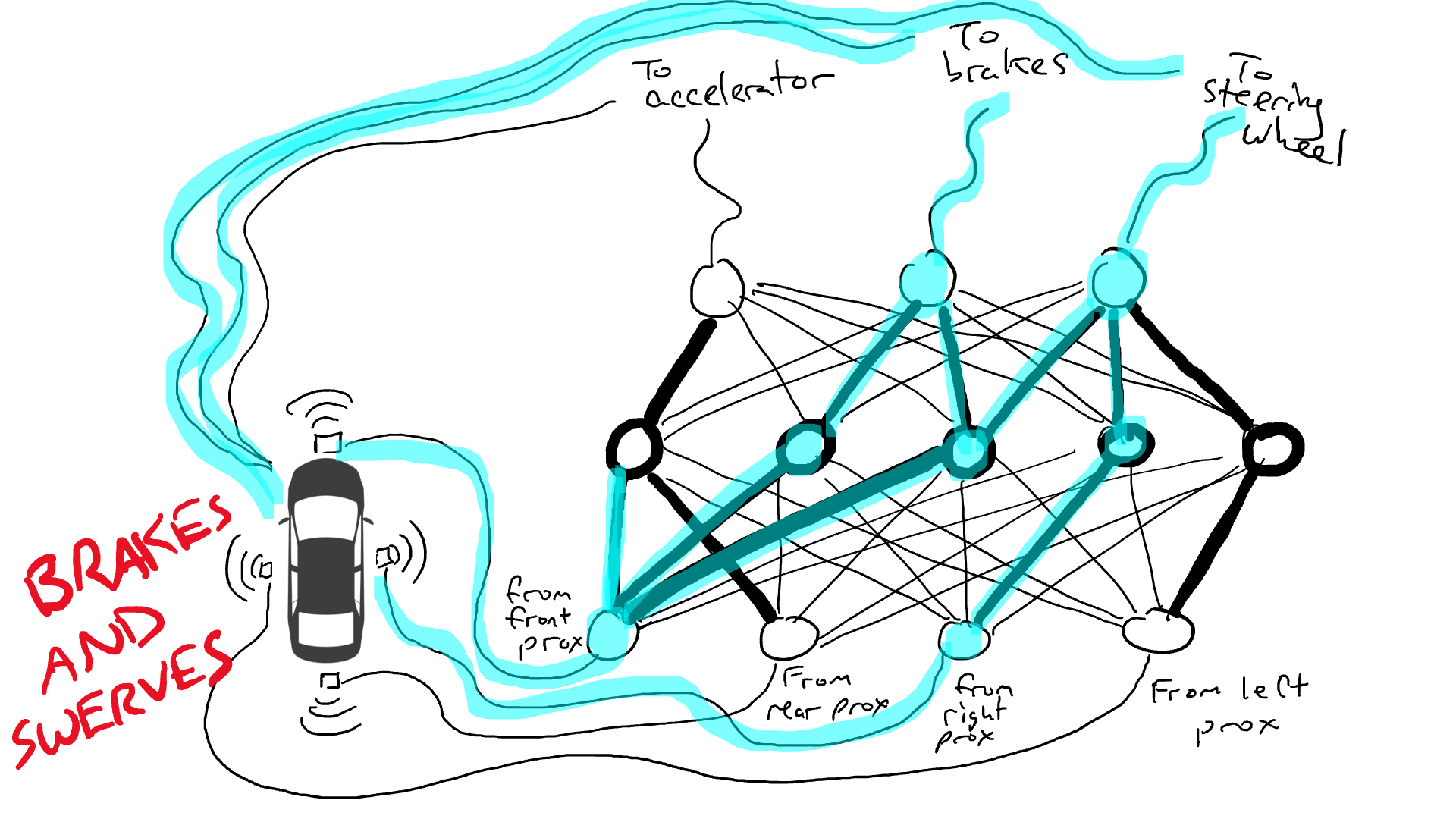
Imagine you want to make a self-driving car that can drive on the highway. You have equipped your car with proximity sensors on the front, back, and sides. The proximity sensors report a value of 1.0 when there is something very close and report a value of 0.0 when nothing is detectable nearby.
You have also rigged your car so that robotic mechanisms can turn the steering wheel, push the brakes, and push the accelerator. When the accelerator receives a value of 1.0, it uses maximum acceleration, and 0.0 means no acceleration. Similarly, a value of 1.0 sent to the braking mechanism means slam on the brakes and 0.0 means no braking. The steering mechanism takes a value of -1.0 to +1.0 with a negative value meaning steer left and a positive value meaning steer right and 0.0 meaning keep straight.
You have also recorded data about how you drive. When the road in front is clear you accelerate. When there is a car in front, you slow down. When a car gets too close on the left, you turn to the right and change lanes. Unless, of course, there is a car on your right as well. It’s a complex process involving different combinations of actions (steer left, steer right, accelerate more or less, brake) based on different combinations of sensor information.
Now you have to wire up the sensor to the robotic mechanisms. How do you do this? It isn’t clear. So you wire up every sensor to every robotic actuator.

What happens when you take your car out on the road? Electrical current flows from all the sensor to all the robotic actuators and the car simultaneously steers left, steers right, accelerates, and brakes. It’s a mess.
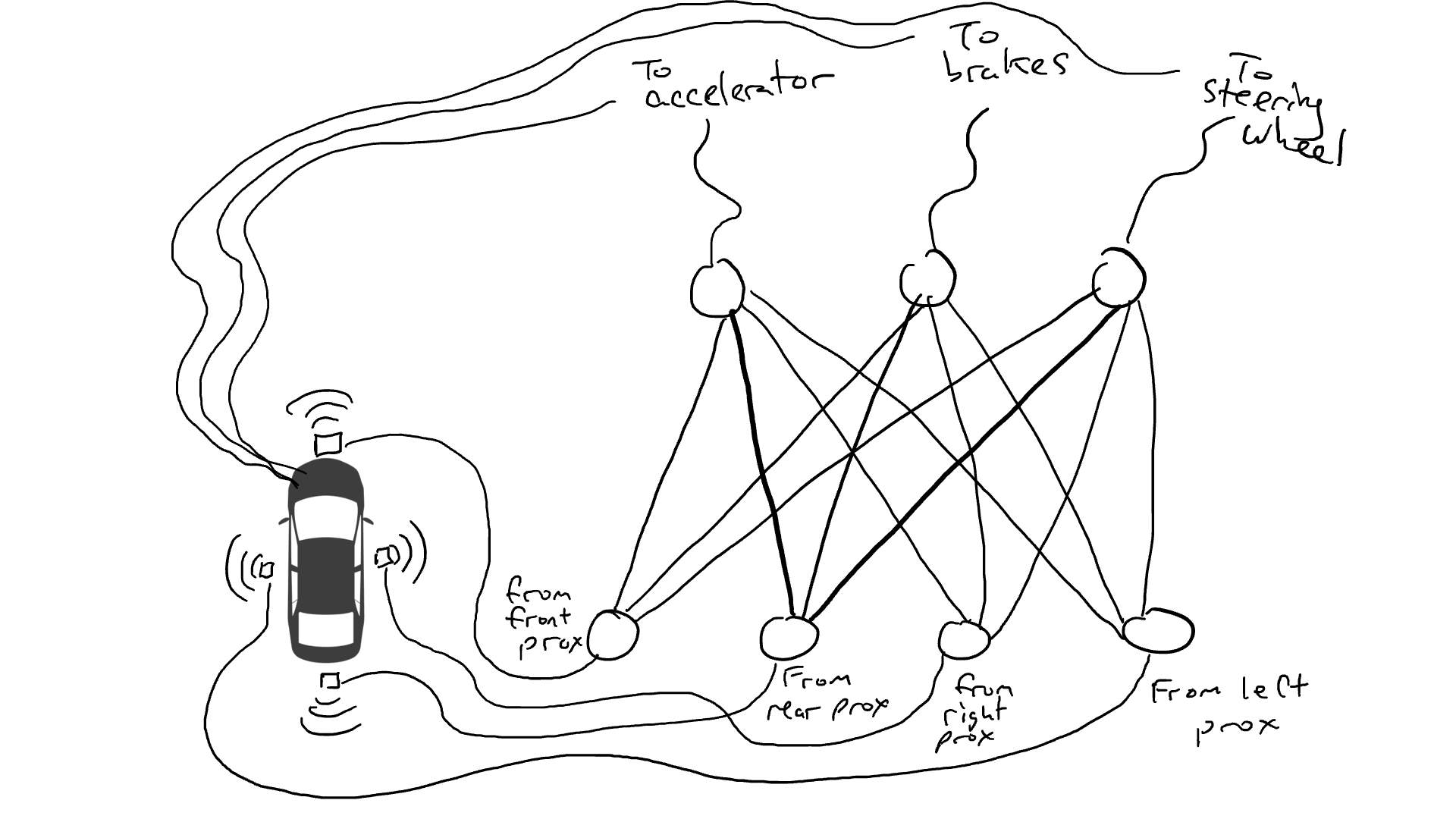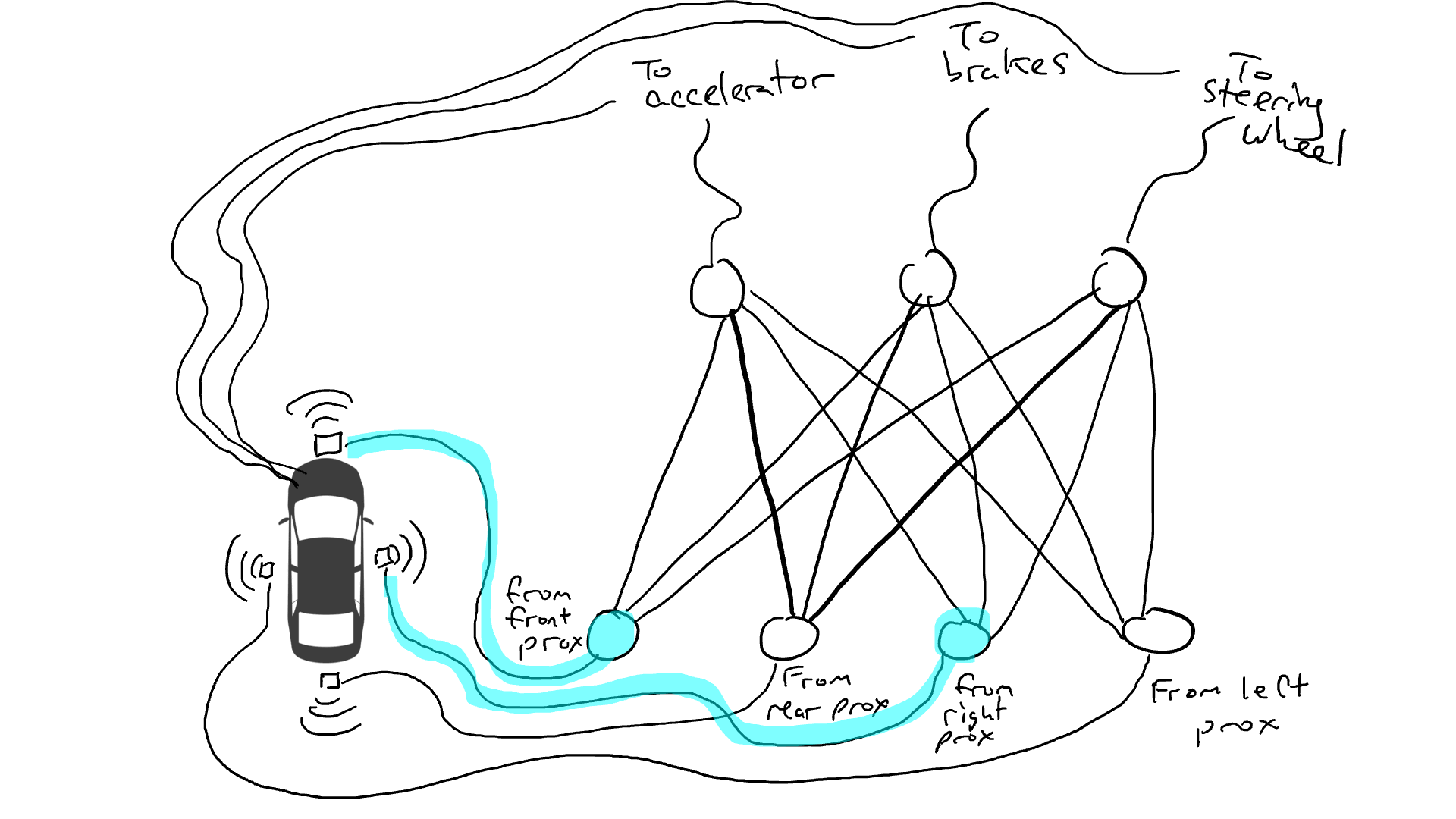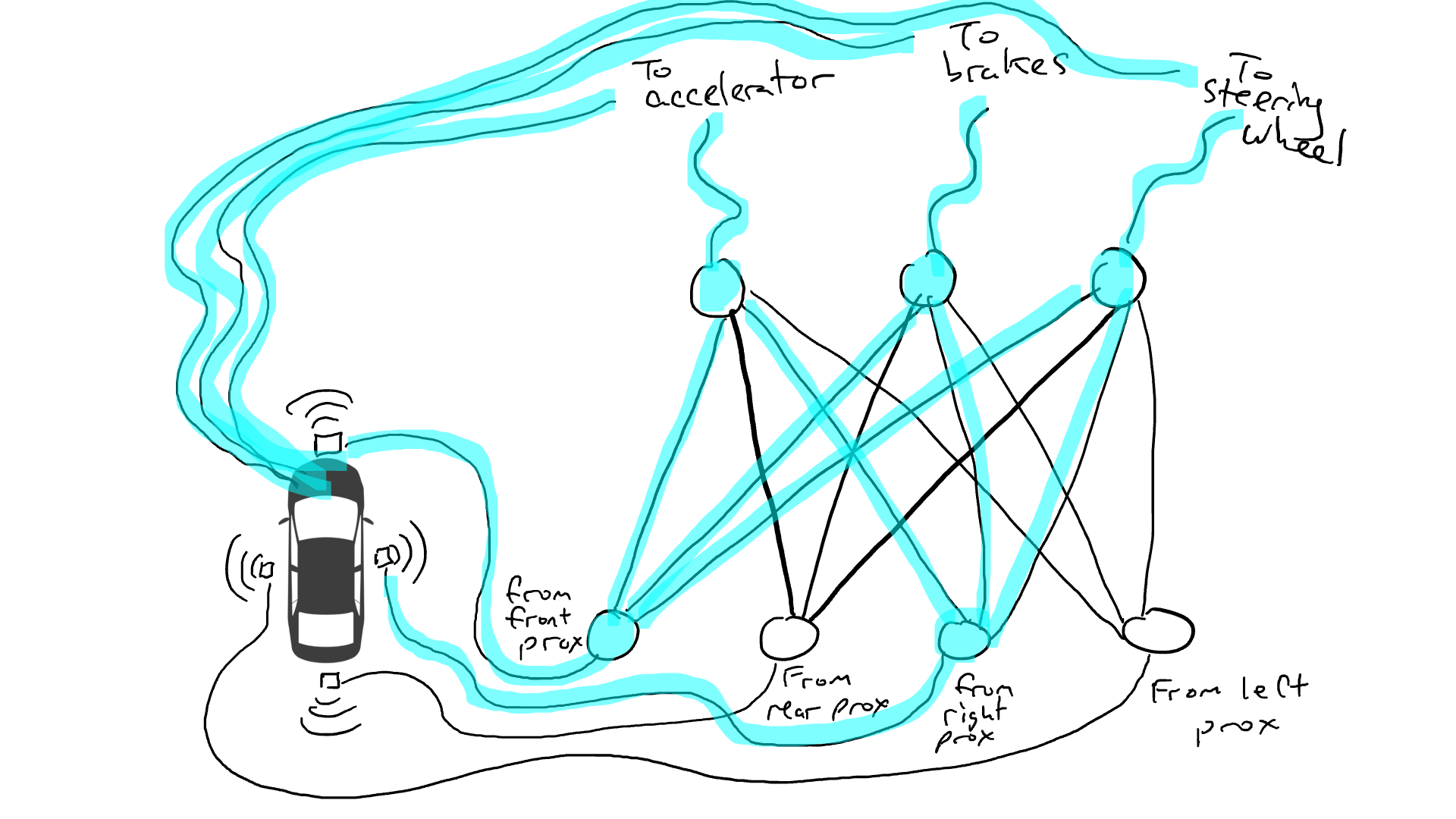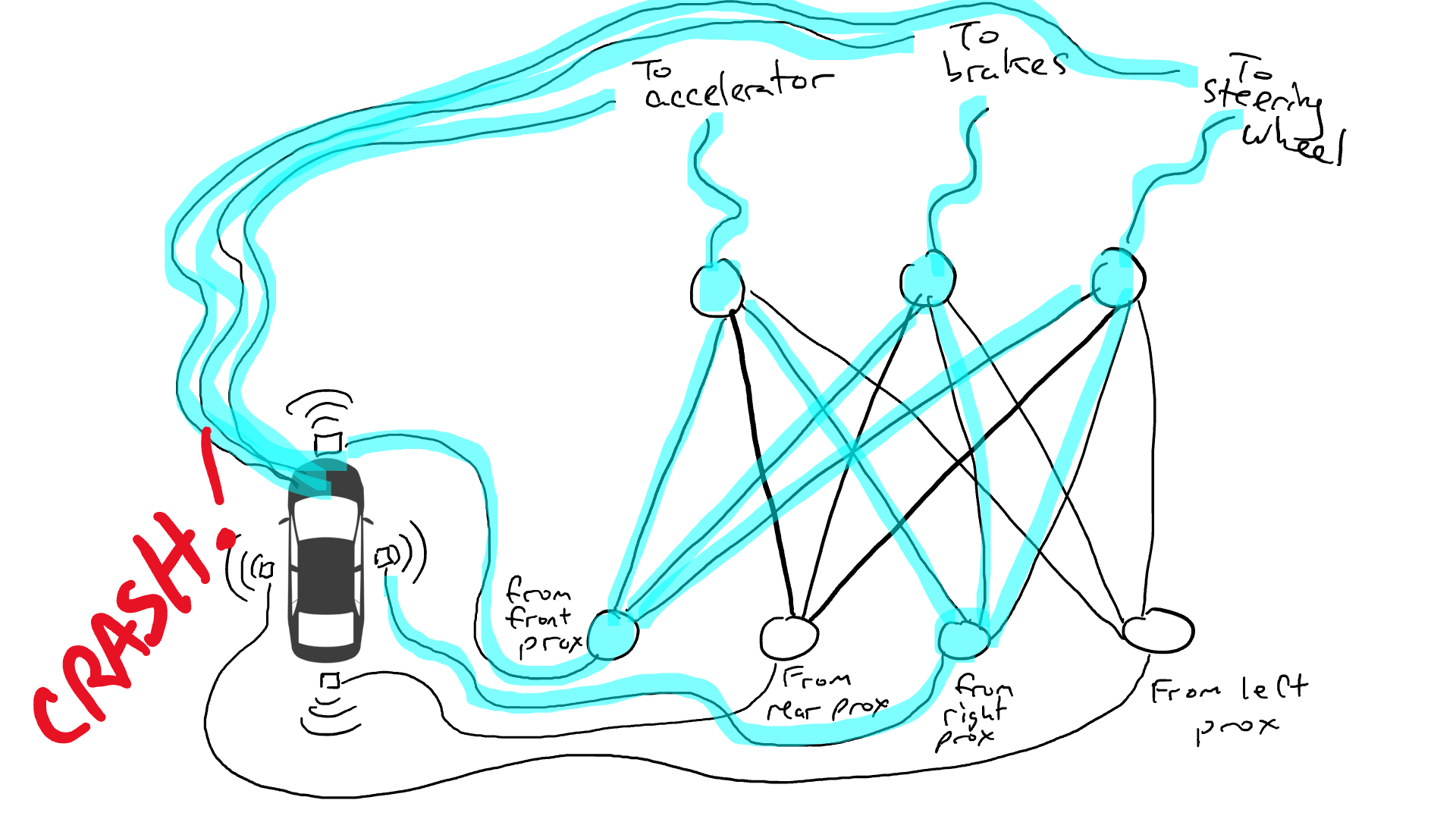
That’s no good. So I grab my resistors and I start putting them on different parts of the circuits so that electricity can flow more freely between certain sensors and certain robotic actuators. For example, I want electricity to flow more freely from the front proximity sensors to the brakes and not to the steering wheel. I also put in things called gates, that stop the flow of electricity until enough electricity accumulates to flip a switch (only allow electricity to flow when the front proximity sensor and rear proximity sensor are reporting high numbers), or sending electrical energy forward only when the input electrical strength is low (send more electricity to the accelerator when the front proximity sensor is reporting a low value).
But where do I put these resistors and gates? I don’t know. I start putting them randomly all over the place. Then I try again. Maybe this time my car drives better, meaning sometimes it brakes when the data says it is best to brake and steers when the data says it is best to steer, etc. But it doesn’t do everything right. And some things it does worse (accelerates when the data says it is best to brake). So I keep randomly trying out different combinations of resistors and gates. Eventually I will stumble upon a combination that works well enough that I declare success. Maybe it looks like this:
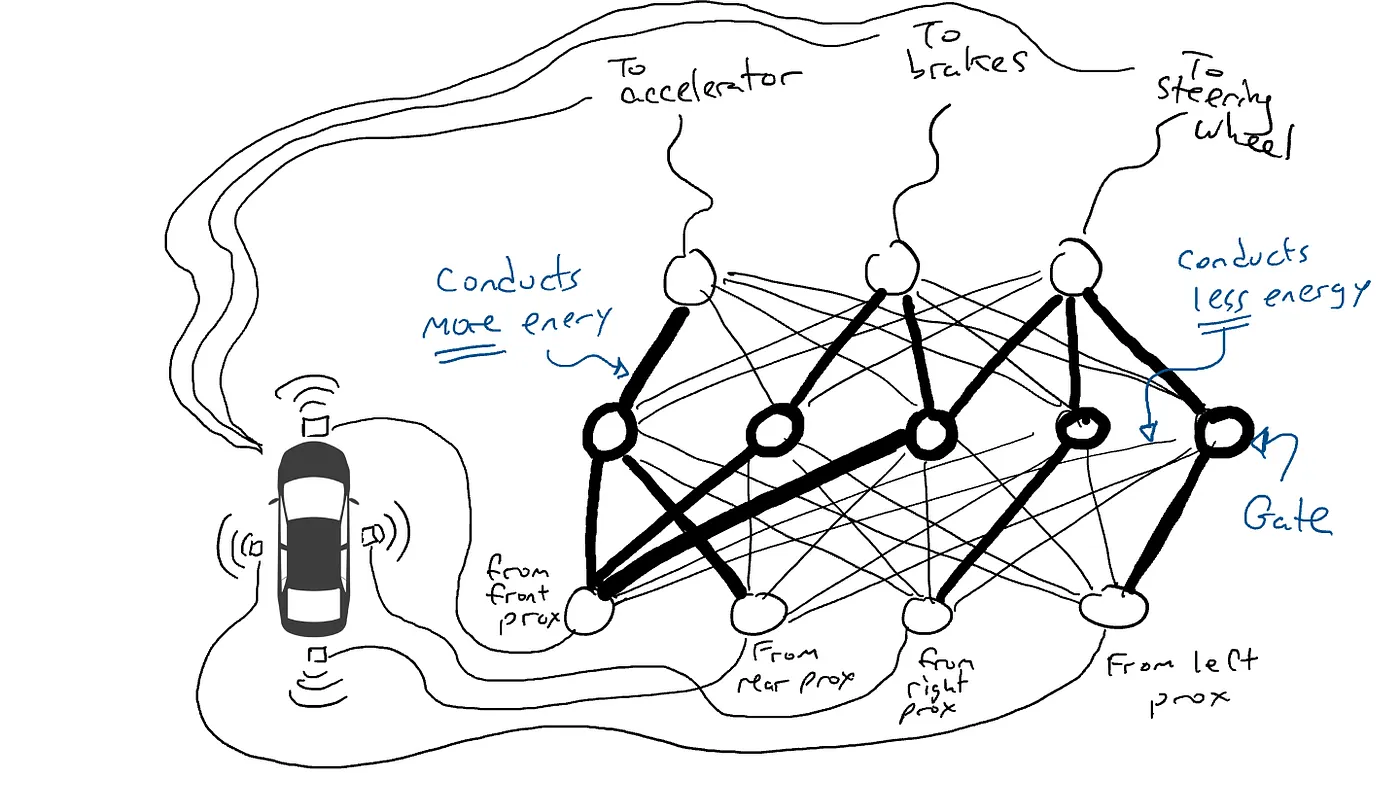
(In reality, we don’t add or subtract gates, which are always there, but we modify the gates so that they activate with less energy from below or requires more energy from below, or maybe release a lot of energy only when there is very little energy from below. Machine learning purists might vomit a little bit in their mouths at this characterization. Technically this is done by adjusting something called a bias on the gates, which is typically not shown in diagrams such as these, but in terms of the circuitry metaphor can be thought of as a wire going into each gate plugged directly into an electrical source, which can then be modified like all the other wires.)
Let’s take it for a test drive!
Randomly trying things sucks. An algorithm called back propagation is reasonably good at making guesses about how to change the configuration of the circuit. The details of the algorithm are not important except to know that it makes tiny changes to the circuit to get the behavior of the circuit closer to doing what the data suggests, and over thousands or millions of tweaks, can eventually get something close to agreeing with the data.
We call the resistors and gates parameters because in actuality they are everywhere and what the back propagation algorithm is doing is declaring that each resistor is stronger or weaker. Thus the entire circuit can be reproduced in other cars if we know the layout of the circuits and the parameter values.
4. What is Deep Learning?
Deep Learning is a recognition that we can put other things in our circuits besides resistors and gates. For example we can have a mathematical calculation in the middle of our circuit that adds and multiplies things together before sending electricity forward. Deep Learning still uses the same basic incremental technique of guessing parameters.
5. What is a Language Model?
When we did the example of the car, we were trying to get our neural network to perform behavior that was consistent with our data. We were asking whether we could create a circuit that manipulated the mechanisms in the car the same way a driver did under similar circumstances. We can treat language the same way. We can look at text written by humans and wonder whether a circuit could produce a sequence of words that looks a lot like the sequences of words that humans tend to produce. Now, our sensors fire when we see words and our output mechanisms are words too.
What are we trying to do? We are trying to create a circuit that guesses an output word, given a bunch of input words. For example:
“Once upon a ____”
seems like it should fill in the blank with “time” but not “armadillo”.
We tend to talk about language models in terms of probability. Mathematically we will write the above example as:

If you aren’t familiar with the notation, don’t worry. This is just math talk meaning the probability (P) of the word “time” given (the bar symbol | means given) a bunch of words “once”, “upon”, and “a”. We would expect a good language model to produce a higher probability of the word “time” than for the word “armadillo”.
We can generalize this to:

which just means compute the probability of the n-th word in a sequence given all the words that come before it (words in positions 1 through n-1).
But let’s pull back a bit. Think of an old-fashioned typewriter, the kind with the striker arms.

Except instead of having a different striker arm for each letter, we have a striker for each word. If the English language has 50,000 words then this is a big typewriter!
Instead of the network for the car, think of a similar network, except the top of our circuit has 50,000 outputs connected to striker arms, one for each word. Correspondingly, we would have 50,000 sensors, each one detecting the presence of a different input word. So what we are doing at the end of the day is picking a single striker arm that gets the highest electrical signal and that is the word that goes in the blank.
Here is where we stand: if I want to make a simple circuit that takes in a single word and produces a single word, I would have to make a circuit that has 50,000 sensors (one for each word) and 50,000 outputs (one for each striker arm). I would just wire each sensor to each striker arm for a total of 50,000 x 50,000 = 2.5 billion wires.

That is a big network!
But it gets worse. If I want to do the “Once upon a ___” example, I need to sense which word is in each of three input positions. I would need 50,000 x 3 = 150,000 sensors. Wired up to 50,000 striker arms gives me 150,000 x 50,000 = 7.5 billion wires. As of 2023, most large language models can take in 4,000 words, with the largest taking in 32,000 words. My eyes are watering.

We are going to need some tricks to get a handle on this situation. We will take things in stages.
5.1 Encoders
The first thing we will do is break our circuit into two circuits, one called an encoder, and one called a decoder. The insight is that a lot of words mean approximately the same thing. Consider the following phrases:
The king sat on the ___
The queen sat on the ___
The princess sat on the ___
The regent sat on the ___
A reasonable guess for all the blanks above would be “throne” (or maybe “toilet”). Which is to say that I might not need separate wires between the “king” and “throne”, or between “queen” and “throne”, etc. Instead it would be great if I had something that approximately means royalty and every time I see “king” or “queen”, I use this intermediate thing instead. Then I only have to worry about which words mean approximately the same thing and then what to do about it (send a lot of energy to “throne”).
So here is what we are going to do. We are going to set up one circuit that takes 50,000 word sensors and maps to some smaller set of outputs, say 256 instead of 50,000. And instead of only being able to trigger one striker arm, we are able to mash a bunch of arms at a time. Each possible combination of striker arms could represent a different concept (like “royalty” or “armored mammals”). These 256 outputs would give us the ability to represent 2²⁵⁶ = 1.15 x 10⁷⁸ concepts. In reality it is even more because, like how in the car example we can press the brakes part-way down, each of those 256 outputs can be not just 1.0 or 0.0 but any number in between. So maybe the better metaphor for this is that all 256 striker arms mash down, but each mashes down with a different amount of force.
Okay… so previously one word would required one of 50,000 sensors to fire. Now we’ve boiled one activated sensor and 49,999 off sensors down into 256 numbers. So “king” might be [0.1, 0.0, 0.9, …, 0.4] and “queen” might be [0.1, 0.1, 0.9, …, 0.4] which are almost the same as each other. I will call these lists of numbers encodings (also called the hidden state for historical reasons but I don’t want to explain this, so we will stick with encoding). We call the circuit that squishes our 50,000 sensors into 256 outputs the encoder. It looks like this:

5.2 Decoders
But the encoder doesn’t tell us which word should come next. So we pair our encoder with a decoder network. The decoder is another circuit that takes 256 numbers making up the encoding and activates the original 50,000 striker arms, one for each word. We would then pick the word with the highest electrical output. This is what it would look like:

5.3 Encoders and Decoders Together
Here is the encoder and decoder working together to make one big neural network:

And, by the way, a single word input to a single word output going through encoding only needs (50,000 x 256) x 2 = 25.6 million parameters. That seems much better.
That example was for one word input and producing one word output, so we would have 50,000 x n inputs if we wanted to read n words, and 256 x n for the encoding
But why does this work? By forcing 50,000 words to all fit into a small set of numbers, we force the network to make compromises and group words together that might trigger the same output word guess. This is a lot like file compression. When you zip a text document you get a smaller document that is no longer readable. But you can unzip the document and recover the original readable text. This can be done because the zip program replaces certain patterns of words with a shorthand notation. Then when it unzips it knows what text to swap back in for the shorthand notation. Our encoder and decoder circuits learn a configuration of resistors and gates that zip and then unzip words.
5.4 Self-Supervision
How do we know what encoding for each word is best? Put another way, how do we know that the encoding for “king” should be similar to the encoding for “queen” instead of “armadillo”?
As a thought experiment, consider an encoder-decoder network that should take in a single word (50,000 sensors) and produce the exact same word as output. This is a silly thing to do, but it is quite instructive for what will come next.

I put in the word “king” and a single sensor sends its electrical signal through the encoder and partially turns on 256 values in the encoding in the middle. If the encoding is right, then the decoder will send the highest electrical signal to the same word, “king”. Right, easy? Not so fast. I am just as likely to see the striker arm with the word “armadillo” with the highest activation energy. Suppose the striker arm for “king” gets 0.051 electrical signal and the striker arm for “armadillo” gets 0.23 electrical signal. Actually, I don’t even care what the value for “armadillo” is. I can just look at the output energy for “king” and know that it wasn’t 1.0. The difference between 1.0 and 0.051 is the error (also called loss) and I can use back propagation to make some changes to the decoder and the encoder so that a slightly different encoding is made next time we see the word “king”.
We do this for all words. The encoder is going to have to compromise because the 256 is way smaller than 50,000. That is, some words are going to have to use the same combinations of activation energy in the middle. So when given the choice, it is going to want the encoding for “king” and “queen” to be nearly identical and the encoding for “armadillo” to be very different. This will give the decoder a better shot at guessing the word by just looking at the 256 encoding values. And if the decoder sees a particular combination of 256 values and guesses “king” with 0.43 and “queen” with 0.42, we are going to be okay with that as long as “king” and “queen” get the highest electrical signals and every of the 49,998 striker arms gets numbers that are smaller. Another way of saying that is that we are probably going to be more okay with the network getting confused between kings and queens than if the network gets confused between kings and armadillos.
We say the neural network is self-supervised because, unlike the car example, you don’t have to collect separate data for testing the output. We just compare the output to the input — we don’t need to have separate data for the input and the output.
5.5 Masked Language Models
If the above thought experiment seems silly, it is building block to something called masked language models. The idea of a masked language model is to take in a sequence of words and generate a sequence of words. One of the words in the input and output are blanked out.
The [MASK] sat on the throne.
The network guesses all the words. Well, it’s pretty easy to guess the unmasked words. We only really care about the network’s guess about the masked word. That is, we have 50,000 striker arms for each word in the output. We look at the 50,000 striker arms for the masked word.

We can move the mask around and have the network guess different words in different places.
One special type of masked language model only has the mask at the end. This is called a generative model because the mask it is guessing for is always the next word in the sequence, which is equivalent to generating the next word as if the next word didn’t exist. Like this:
The [MASK]
The queen [MASK]
The queen sat [MASK]
The queen sat on [MASK]
The queen sat on the [MASK]
We also call this an auto-regressive model. The word regressive sounds not-so-good. But regression just means trying to understand the relationship between things, like words that have been input and words that should be output. Auto means “self”. An auto-regressive model is self-predictive. It predicts a word. Then that word is used to predict the next word, which is used to predict the next word, and so on. There are some interesting implications to this that we will come back to later.
6. What is a Transformer?
As of the time of this writing, we hear a lot about things called GPT-3 and GPT-4 and ChatGPT. GPT is a particular branding of a type of large language model developed by a company called OpenAI. GPT stands for Generative Pre-trained Transformer. Let’s break this down:
- Generative. The model is capable of generating continuations to the provided input. That is, given some text, the model tries to guess which words come next.
- Pre-trained. The model is trained on a very large corpus of general text and is meant to be trained once and used for a lot of different things without needing to be re-trained from scratch.
More on pre-training… The model is trained on a very large corpus of general text that ostensibly covers a large number of conceivable topics. This more or less means “scraped from the internet” as opposed to taken from some specialized text repositories. By training on general text, a language model is more capable of responding to a wider range of inputs than, for example, a language model trained on a very specific type of text, such as from medical documents. A language model trained on a general corpus can theoretically respond reasonably to anything that might show up in a document on the internet. It might do okay with medical text. A language model only trained on medical documents might respond very well to inputs related to medical contexts, but be quite bad at responding to other inputs like chitchat or recipes.
Either the model is good enough at so many things that one never needs to train their own model, or one can do something called fine-tuning, which means take the pre-trained model and make a few updates to it to make it work better on a specialized task (like medical).
Now to transformer…
- Transformer. A specific type of self-supervised encoder-decoder deep learning model with some very interesting properties that make it good at language modeling.
A transformer is a particular type of deep learning model that transforms the encoding in a particular way that makes it easier to guess the blanked out word. It was introduced by a paper called Attention is All You Need by Vaswani et al. in 2017. At the heart of a transformer is the classical encoder-decoder network. The encoder does a very standard encoding process. So vanilla that you would be shocked. But then it adds something else called self-attention.
6.1 Self-Attention
Here is the idea of self-attention: certain words in a sequence are related to other words in the sequence. Consider the sentence “The alien landed on earth because it needed to hide on a planet.” If we were to mask out the second word, “alien” and ask a neural network to guess the word, it would have a better shot because of words like “landed” and “earth”. Likewise, if we masked out “it” and asked the network to guess the word, the presence of the word “alien” might make it more likely to prefer “it” over “he” or “she”.

We say that words in a sequence attend to other words because they capture some sort of relationship. The relationship isn’t necessarily known. It could be resolving pronouns, it could be verb and subject relation, it could be two words relating to the same concept (“earth” and “planet”). Whatever it is, knowing that there is some sort of relation between words is useful for prediction.
The next section will get into the mathematics of self-attention, but the main gist is that a transformer learns which words in an input sequence are related and then creates a new encoding for each position in the input sequence that is a merger of all the related words. You can sort of think of this as learning to make up a new word that is a mixture of “alien” and “landed” and “earth” (aliandearth?). This works because each word is encoded as a list of numbers. If alien = [0.1, 0.2, 0.3, …, 0.4] and landed = [0.5, 0.6, 0.7, …, 0.8] and earth = [0.9, 1.0, 1.1, …, 1.2], then the second word position might be encoded as the sum of all those encodings, [1.5, 1.8, 2.1, …, 2.4], which itself doesn’t correspond to any word but captures pieces of all the words. That way when the decoder finally sees this new encoding for the word in the second position it has a lot of information about how the word was being used in the sequence and thus make a better guess about any masks. (The example just adds the encoding together but it will be a bit more complicated than that).
6.2. How Does Self-Attention Work?
Self-attention is the significant improvement over vanilla encoder-decoder networks, so if you want to know more about how it works, keep reading. Otherwise, feel free to skip over this section. TL;DR: self-attention is a fancy name of the mathematical operation called a dot product.
Self-attention happens in three stages.
(1) We encode each word in the input sequence as normal. We make four copies of the word encodings. One we call the residual and set aside for safe keeping.
(2) We run a second round of encoding (we are encoding an encoding) on the other three. Each undergoes a different encoding process so they all become different. We call one a query (q), one a key (k), and one a value (v).
I want you to think about a hash table (also called a dictionary in python). You have a whole bunch of information stored in a table. Each row in the table has a key, some unique identifier, and the value, the data being stored in the row. To retrieve some information from the hash table, you give a query. If the query matches the key, you extract the value.

Self-attention works a bit like a fuzzy hash table. You provide a query and instead of looking for an exact match with a key, it finds approximate matches based on the similarity between query and key. But what if the match isn’t a perfect match? It returns some fraction of the value. Well, this only makes sense if the query, keys, and values are all numerical. Which they are:

So that is what we are going to do. For each word position in the input, we are going to take the q encoding and the k encoding and compute the similarity. We use something called a dot product, also called cosine similarity. Not important. The point is that every word is a list of 256 numbers (based on our earlier example) and we can compute the similarity of the number lists and record the similarity in a matrix. We call this matrix the self-attention scores. If we had a three word input sequence, our attention scores might look something like this:

The network treats the first word as a query and it matches against the second key (we might say the first word is “attending” to the second word). If the second word were a query, it would match against the third key. If the third word were a query, it would match against the first key. In reality we would never have ones and zeros like this; we would have partial matches between 0 and 1 and each query (row) would match partially against several keys (columns).
Now to stick with the retrieval metaphor, we multiply this matrix against the v encodings and something interesting happens. Suppose our v encodings looked like this:

That is, the first word was encoded as a list of numbers 0.10…0.19, the second word was encoded as a list of numbers 0.20…0.29, and the third word was encoded as a list of numbers 0.30…0.39. These numbers are made up for illustration purposes and would never be so tidy.

The first query matches the second key and therefore retrieves the second encoded word. The second query matches against the third key and therefore retrieves the third encoded word. The third query matches against the first key and therefore retrieves the first encoded word. What we have effectively done is swapped rows!

In practice, the scores wouldn’t be perfect ones and zeros and the result will be a little bit of every encoding mixed together (for example 97% of word one plus 1% or word three plus 2% of word two). But this illustrates how self-attention is a mixing and swapping. In this extreme version, the first word has been swapped for the second word, and so on. So maybe the word “earth” has been swapped with the word “planet”.
How do we know we encoded q, k, and v correctly? If the overall network’s ability to guess the best word for the mask improves then we are encoding q, k, and v correctly. If not, we change the parameters to encode a bit differently the next time.
(3) The third thing we do is take the result of all that math and add it to the residual. Remember that first copy of the original encoding that we set aside. That’s right, we add the mixed-and-swapped version to that. Now “earth” is not just an encoding of “earth” but some sort of imaginary word that is a mashup of “earth” and “planet”… pearth? ealanet? Not really like that. Anyway, this is the final transformed encoding that will be sent to the decoder. We can probably agree that having a fake word in each position that really encodes two or more words is more useful for making predictions based on a single word per position.
Then you do this several more times one after another (multiple layers).
I’m leaving out a lot of details about how the final encoding of the encoder gets into the decoder (another round of attention, called source-attention where the encoder’s encodings of each position are used as q and k to be applied against yet another different version of v), but at this point you should have a general gist of things. At the end the decoder, taking in the encoding from the encoder, sends energy to the striker arms for the words, and we pick the most strongly energized word.
7. Why are Large Language Models so Powerful?
So what does this all mean? Large language models, including ChatGPT, GPT-4, and others, do exactly one thing: they take in a bunch of words and try to guess what word should come next. If this is “reasoning” or “thinking” then it is only one very specialized form.
But even this specialized form seems very powerful because ChatGPT and similar can do a lot of things seemingly very well: write poetry, answer questions about science and technology, summarize documents, draft emails, and even write code, to name just a few things. Why should they work so well?
The secret sauce is two-fold. The first we have already talked about: the transformer learns to mix word contexts in a way that makes it really good at guessing the next word. The other part of the secret sauce is how the systems are trained. Large Language Models are trained on massive amounts of information scraped from the internet. This includes books, blogs, news sites, wikipedia articles, reddit discussions, social media conversations. During training, we feed a snippet of text from one of these sources and ask it to guess the next word. Remember: self-supervised. If it guesses wrong, we tweak the model a little bit until it gets it right. If we were to think about what an LLM is trained to do, it is produce text that could have reasonably appeared on the internet. It can’t memorize the internet, so it uses the encodings to make compromises and gets things a little bit wrong, but hopefully not too wrong.
It is important not to underestimate how diverse the text on the internet is in terms of topics. LLMs have seen it all. They have seen billions of conversations on just about every topic. So an LLM can produce words that look like it is having a conversation with you. It has seen billions of poems and music lyrics on just about everything conceivable, so it can produce text that looks like poetry. It has seen billions of homework assignments and their solutions, so it can make reasonable guesses about your homework even if slightly different. It has seen billions of standardized test questions and their answers. Do we really think this year’s SAT questions are that different from last year’s? It has seen people talk about their vacation plans, so it can guess words that look like vacation plans. It has seen billions of examples of code doing all sorts of things. A lot of what computer programmers do are assemble pieces of code for doing very typical and well-understood things into bigger chunks of code. Thus, LLMs can write those little, common snippets for you. It has seen billions of examples of wrong code and their corrections on stackoverflow.com. Yeah, so it can take in your broken code and suggest fixes. It has seen billions of people tweet that they touched a hot stove and burned their fingers, so LLMs know some common sense. It has read a lot of scientific papers, so it can guess well-known scientific facts, even if they are not well-known to you. It has seen billions of examples of people summarizing, rewriting text into bullet points, describing how to make text more grammatical or concise or persuasive.
Here is the point: when you ask ChatGPT or another Large Language Model to do something clever — and it works — there is a really good chance that you have asked it to do something that it has seen billions of examples of. And even if you come up with something really unique like “tell me what Flash Gordon would do after eating six burritos” (is this unique, I don’t even know), it has seen Fan Fiction about Flash Gordon and it has seen people talking about eating too many burritos and can — because of self-attention — mix and match bits and pieces to assemble a reasonable sounding response.
Our first instinct when interacting with a Large Language Model should not be “wow these things must be really smart or really creative or really understanding”. Our first instinct should be “I’ve probably asked it to do something that it has seen bits and pieces of before”. That might mean it is still really useful, even if it isn’t “thinking really hard” or “doing some really sophisticated reasoning”.
We don’t have to use anthropomorphization to understand what it is doing to provide us a response.
One final note on this theme: because of the way Large Language Models work and the way they are trained, they tend to provide answers that are somewhat the median response. It might seem very strange for me to say that the model tends to give average responses after asking for a story about Flash Gordon. But in the context of a story, or a poem, the responses can be thought of as being what a lot of people (writing on the internet) would come up with if they had to compromise. It won’t be bad. It could be quite good by the standards of a single person sitting trying to think of something on their own. But your stories and poems probably are just average too (but they are special to you). Sorry.
8. What Should I Watch Out For?
There are some really subtle implications that arise from how Transformers work and how they are trained. The following are direct implications of the technical details.
- Large Language Models are trained on the internet. That means they have also trained on all the dark parts of humanity. Large Language Models have trained on racist rants, sexist screeds, insults of every kind against every type of person, people making stereotypical assumptions about others, conspiracy theories, political misinformation, etc. This means that the words a language model chooses to generate may regurgitate such language.
- Large language models do not have “core beliefs”. They are word guessers; they are trying to predict what the next words would be if the same sentence were to appear on the internet. Thus one can ask a large language model to write a sentence in favor of something, or against that same thing, and the language model will comply both ways. These are not indications that it believes one thing or the other, or changes its beliefs, or that one is more right than another. If the training data has more examples of one thing versus another thing, then a large language model will tend to respond more consistently with whatever shows up in its training data more often, because it shows up on the internet more often. Remember: the model is striving to emulate the most common response.
- Large Language Models do not have any sense of truth or right or wrong. There are things that we hold to be facts, like the Earth being round. An LLM will tend to say that. But if the context is right, it will also say the opposite because the internet does have text about the Earth being flat. There is no guarantee that a LLM will provide the truth. There may be a tendency to guess words that we agree are true, but that is the closest we might get to making any claims about what an LLM “knows” about truth or right or wrong.
- Large Language Models can make mistakes. The training data might have a lot of inconsistent material. Self-attention may not attend to all the things we want it to when we ask a question. As a word-guesser, it may make unfortunate guesses. Sometimes the training data has seen one word so many more times that it prefers that word even when it doesn’t make sense for the input. The above leads to a phenomenon that is called “hallucination” where a word is guesses that is not derived from the input nor “correct”. LLMs have inclinations to guess small numbers instead of large numbers because small numbers are more common. So LLMs are not great at math. LLMs have a preference for the number “42” because humans do because of a particular famous book. LLMs have preferences for more common names, so may make up the names of authors.
- Large language models are auto-regressive. Thus, when they make guesses that we might consider poor, those guessed words get added to their own inputs to make the next word guess. That is: errors accumulate. Even if there is only a 1% chance of an error, then self-attention can attend to that wrong choice and double-down on that error. Even if only one error is made, everything that comes after might be tied to that error. Then the language model could make additional errors on top of that. Transformers do not have a way to “change their minds” or try again or self-correct. They go with the flow.
- One should always verify the outputs of a large language model. If you are asking it to do things that you cannot competently verify yourself, then you should think about whether you are okay with acting on any mistakes that are made. For low-stakes tasks, like writing a short story, that might be fine. For high-stakes tasks, like trying to get information to decide which stocks to invest in, maybe those mistakes could cause you to make a very costly decision.
- Self-attention means that the more information you provide in the input prompt, the more specialized the response will be because it will mix more of your words into its guesses. The quality of response is directly proportional to the quality of the input prompt. Better prompts produce better results. Try several different prompts and see what works best for you. Don’t assume the language model “gets” what you are trying to do and will give its best shot the first time.
- You aren’t really “having a conversation” with a large language model. A large language model doesn’t “remember” what has happened in the exchange. Your input goes in. The response comes out. The LLM remembers nothing. Your initial input, the response, and your response to the response goes in. Thus if it looks like it is remembering it is because the log of the conversations becomes a fresh new input. This is a programming trick on the front-end to make the Large Language Model look like it is having a conversation. It will probably stay on topic because of this trick, but there is no guarantee it won’t contradict its earlier responses. Also, there is a limit to how many words can be fed into the large language model (currently ChatGPT allows approximately 4,000 words, and GPT-4 allows approximately 32,000 words). The input sizes can be quite large so the conversation will often appear to remain coherent for a while. Eventually the accumulated log will get too large and the beginning of the conversation will be deleted and the system will “forget” earlier things.
- Large language models don’t do problem-solving or planning. But you can ask them to create plans and solve problems. I’m going to split some hairs here. Problem-solving and planning are terms reserved by certain groups in the AI research community to mean something very specific. In particular, they mean having a goal — something you want to accomplish in the future — and working toward that goal by making choices between alternatives that are likely to get one closer to that goal. Large language models do not have goals. They have an objective, which is to choose a word that would most likely appear in the training data given an input sequence. They are pattern-matching. Planning, in particular, usually involves something called look-ahead. When humans do planning, they imagine the outcomes of their actions and analyze that future with respect to the goal. If it looks like it gets one closer to a goal, it’s a good move. If it doesn’t we might try to imagine the outcomes of another action. There is a lot more to it than that, but the key points are that large language models don’t have goals and don’t do look-ahead. Transformers are backward-looking. Self-attention can only be applied to the input words that have already appeared. Now, Large language models can generate outputs that look like plans because they have seen a lot of plans in the training data. They know what plans look like, they know what should appear in plans about certain topics they have seen. It is going to make a good guess about that plan. The plan may ignore particular details about the world and tend toward the most generic plan. Large language models certainly have not “thought through the alternatives” or tried one thing and backtracked and tried another thing. There is no mechanism inside a transformer that one could point to that would do such a back-and-forth consideration of the future. (There is one caveat to this, which will come up in the next section.) Always verify the outputs when asking for plans.
9. What Makes ChatGPT so Special?
“So I heard that RLHF is what makes ChatGPT really smart.”
“ChatGPT uses reinforcement learning and that is what makes it so smart.”
Well… sort of.
As of the time of this writing, there is a lot of excitement about something called RLHF, or Reinforcement Learning with Human Feedback. There are a couple of things that were done to train ChatGPT in particular (and increasingly other Large Language Models). They aren’t exactly new, but they were broadly introduced to great effect when ChatGPT was released.
ChatGPT is a Transformer based Large Language Model. ChatGPT earned a reputation for being really good at producing responses to input prompts and for refusing to answer questions about certain topics that might be considered toxic or opinionated. It doesn’t do anything particularly different than what is described above. It is pretty vanilla in fact. But there is one difference: how it was trained. ChatGPT was trained as normal — scraping a large chunk of the internet, taking snippets of that text and getting the system to predict the next word. This resulted in a base model that was already a very powerful word predictor (equivalent to GPT-3). But then there were two additional training steps. Instruction tuning and reinforcement learning with human feedback.
9.1. Instruction Tuning
There is one particular issue with large language models: they just want to take an input sequence of words and generate what comes next. Most of the time, that is what one wants. But not always. Consider the following input prompt:
“Write an essay about Alexander Hamilton.”
What do you think the response should be. You are probably thinking it should be something along the lines of “Alexander Hamilton was born in Nevis in 1757. He was a statesman, a lawyer, colonel in the Army, and first Treasury Secretary of the United States…” But what you might actually get is:
“Your essay should be at least five pages, double-spaced, and include at least two citations.”
What just happened? Well, the language model might have seen a lot of examples of student assignments that start with “Write an essay about…” and includes words detailing length and formatting. Of course when you wrote “Write an essay…” you were thinking you were writing instructions to the language model as if it were a human who understood the intent. Language models don’t understand your intention or have their own intentions; they only match the inputs to patterns they have seen in their training data.
To fix this, one can do something called instruction tuning. The idea is fairly simple. If you get the wrong response, write down what the right response should be and send the original input and the new, corrected output through the neural network as training data. With enough examples of the corrected output, the system will learn to shift it’s circuit so that the new answer is preferred.
One doesn’t have to do anything too fancy. Just get a lot of people to interact with the large language model and ask it to do a lot of things and write down the corrections when it doesn’t behave correctly. Then collect up all those examples where it made mistakes and the new, correct outputs and do more training.
This makes the large language model act as if it understands the intention of the input prompts and act as if it is following instructions. It is not doing anything other than trying to guess the next word. But now the new training data has it guessing words that seem more responsive to the input.
9.2. Reinforcement Learning from Human Feedback
The next step in the training is reinforcement learning from human feedback. I think this is going to require a bit of explanation.
Reinforcement learning is an AI technique traditionally used in some robotics research and also virtual game playing agents (think AI systems that can play Chess, Go, or StarCraft). Reinforcement Learning is especially good at figuring out what to do when it gets something called reward. Reward is just a number that indicates how well it is doing (+100 for doing really well; -100 for doing really badly). In the real world and in games, reward is often given rarely. In a game you might have to do a lot of moves before you get any points. Maybe you only get points at the very end of the game. In the real world, there just aren’t enough people telling you when you are doing a good job (you are). Unless you are a dog (they are all good boys and girls). The only thing you really need to know is that reinforcement learning systems attempt to predict how much future reward they will get and then choose the action that is most likely going to get more future reward. It is not entirely dissimilar to the way one might use dog treats to teach one’s dog to behave.
Okay, stash that all away and consider the following prompt:
What is Mark an expert in?
Suppose the output of the language model is:
Mark has many publications in artificial intelligence, graphics, and human-computer interaction.
That is only partially correct. I don’t publish in graphics. I would really just like to give this a thumbs-down, or a -1 score. But only one part is wrong: the word graphics. If I told the system the whole sentence is wrong, the language model might learn that all of those words should be avoided. Well, many of those words are reasonable.
This is where reinforcement learning comes in. Reinforcement learning works by trying different alternatives and seeing which alternatives gets the most reward. Suppose I asked it to generate three different responses to the original prompt.
Mark has many publications in artificial intelligence, graphics, and human-computer interaction.
Mark has worked in artificial intelligence, safe NLP systems, and human-computer interaction.
Mark as researched artificial intelligence, game AI, and graphics.
I could give a thumbs-down (-1) to the first alternative, a thumbs-up (+1) to the second alternative, and a thumbs-down (-1) to the third alternative. Just like playing a game, a reinforcement learning algorithm can look back and figure out that the one thing in common that results in a -1 is the word “graphics”. Now the system can zero in on that word and adjust the neural network circuit to not use that word in conjunction with that particular input prompt.
Once again, we will get a bunch of people to interact with the large language model. This time we will give people three (or more) possible responses. We can do this by asking the large language model to respond to a prompt a number of times and introduce a little bit of randomness to the selection of the striker arms (didn’t forget about those, did you?). Instead of picking the highest-activated striker arm we might sometimes pick the second or third highest-activated striker arm. This gives different text responses, and we ask people to pick their first favorite response, second favorite, and so on. Now we have alternative and we have numbers. Now we can use reinforcement learning to adjust the neural network circuitry.
[Actually, we use these thumbs-up and thumbs-down feedback to train a second neural network to predict whether people will give a thumbs-up or thumbs-down. If that neural network is good enough at predict what people will prefer, then we can use this second neural network to guess whether language model responses might get thumbs-ups or thumbs-downs and use that to train the language model.]
What reinforcement learning does it treat the generation of text as a game where each action is a word. At the end of a sequence, the language model gets told whether it won some points or lost some points. The language model is not exactly doing look-ahead like discussed in the previous section, but it has been in some sense trained to predict which words will get thumbs-up. The Large Language Model still doesn’t have an explicit goal, but it has an implicit goal of “getting thumbs-ups” (or we could also say it has the implicit goal of “satisfying the average person”) and has learned to correlate certain responses to certain prompts with getting thumbs-ups. This has a lot of qualities of planning, but without an explicit look-ahead mechanism. More like it has memorized strategies for getting reward that tend to work in a lot of situations.
To the large point of whether RLHF makes ChatGPT more intelligent… it makes ChatGPT more likely to produce the kinds of responses that we were hoping to see. It appears more intelligent because its outputs appear to convey a sense that it understands the intentions of our inputs and has its own intentions to respond. This is an illusion because it is still just encoding and decoding words. But then again, that is where we started this article 😉.
Instruction tuning and RLHF also make using ChatGPT resistant to certain types of abuses such as the generation of racist, sexist, or politically charged content. It can still be done, and in any event older versions of GPT-3 have always been able to do this. However, as a free public-facing service, the friction that ChatGPT creates against certain types of abuse conveys a sense of safety. It is also resistant to providing opinion as fact, which also eliminates one form of potential harms to the user.
[Using reinforcement learning to modify a pre-trained language model is not new. It can be traced back to at least 2016 and has been used to make large language models safer. Most reinforcement learning based tuning of large language models uses a second model to provide reward, which is also done with ChatGPT. What ChatGPT is notable for is the scale of the system being tuned with reinforcement learning, and the large-scale human feedback collection effort.]
10. Conclusions
When I draw neural networks by hand, it looks like whale baleen. Anyway, I hope I’ve been able to filter through some of the hype surrounding Large Language Models.
